


近日,由普林斯顿大学牵头,联合清华大学、北京大学、上海交通大学、斯坦福大学,以及英伟达、亚马逊、Meta FAIR 等多家顶尖机构的研究者共同推出了新一代开源数学定理证明模型——Goedel-Prover-V2。
该项目的 32B 旗舰模型在多个自动数学定理证明的主要基准测试上均大幅超过之前的最先进开源模型 DeepSeek-Prover-V2-671B;而 8B 小尺寸模型在特定基准上,性能表现与 DeepSeek-Prover-V2-671B 持平,展示了其在效率和能力上的新突破。

-
项目主页:
http://blog.goedel-prover.com -
HuggingFace 模型下载:
https://huggingface.co/Goedel-LM/Goedel-Prover-V2-32B
主要成果
MiniF2F 性能新高:其 32B 旗舰模型在 MiniF2F 测试中,Pass@32 (每道测试题目尝试 32 次;pass 数越小,计算开销越小)的正确率相较于之前的 SOTA 模型 DeepSeek-Prover-V2-671B 提升了 8.0%。
小而强:8B 参数模型的性能表现与之前 671B 参数的 SOTA 模型持平。
登顶 PutnamBench:在极具挑战性的 PutnamBench (普特南数学竞赛基准)上,该模型排名第一。

项目简介
Goedel-Prover-V2 立足于形式化推理,即以精确、无歧义的形式语言(Formal Language)来进行数学推理,完整数学定理证明,整个推理和证明过程可被机器自动验证。目前,最主流的形式化证明语言 Lean 已经被广泛的数学家群体接受。
Goedel-Prover-V2 的开发流程基于标准的专家迭代(expert iteration)与强化学习,并引入了三项关键创新:
-
分层式数据合成 (Scaffolded data synthesis):通过自动合成难度渐进递增的证明任务来训练模型,让模型能够循序渐进地处理更复杂的定理。
-
验证器引导的自我修正 (Verifier-guided self-correction):模型通过利用 Lean 编译器的反馈,学习迭代地修正自身生成的证明,模拟人类自我修正的过程。
-
模型平均 (Model averaging):融合不同训练节点的模型权重,以提升模型的鲁棒性与综合性能。
基于这些方法,该项目的较小模型 Goedel-Prover-V2-8B 在 MiniF2F 测试集上(Pass@32)达到了 83.3% 的通过率,甚至超越此前模型参数量超过 80 倍的 SOTA 模型 DeepSeek-Prover-V2-671B 的性能。其旗舰模型 Goedel-Prover-V2-32B 更是将此项指标提升至 88.1% (标准模式)和 90.4% (自我修正模式),大幅超越了所有先前的 SOTA 模型。
在 PutnamBench 上,开启自我修正模式的旗舰模型仅使用 Pass@64 就解决了 64 个问题,用远远更小的计算开销超过了 DeepSeek-Prover-V2-671B 在 Pass@1024 下解决 47 个问题的记录。
性能表现
基准测试结果
自我修正模式:模型先生成初始证明,再利用 Lean 编译器的反馈进行两轮自我修正。这一过程仍然保持了高效:总的输出长度(包括初始证明和两轮修正)仅仅从标准的 32K tokens 略微增加到 40K tokens。
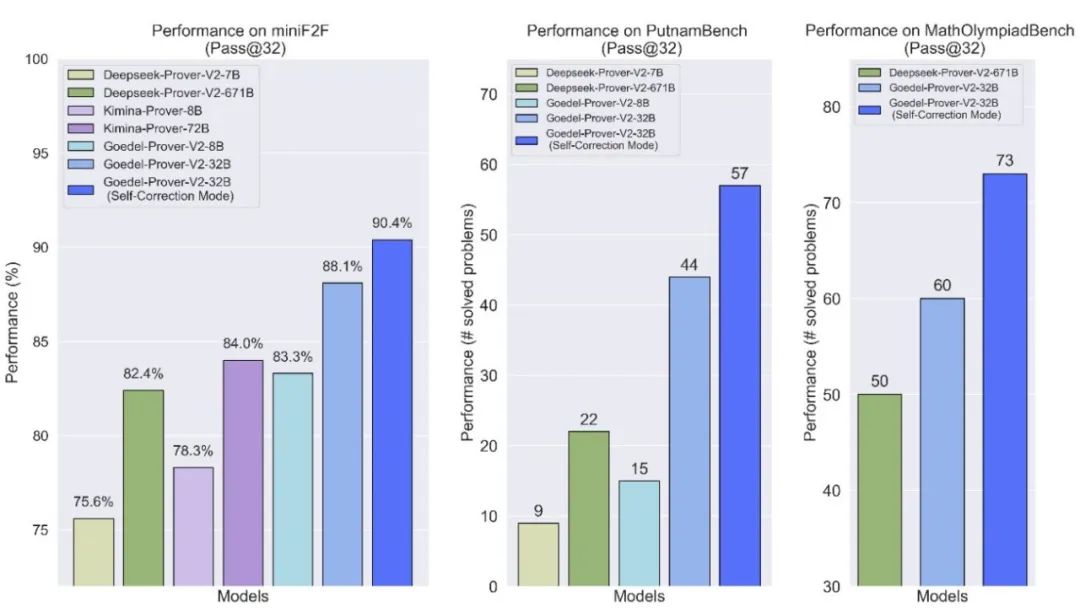
图 1: 在 MiniF2F、PutnamBench、以及新发布的 MathOlympiadBench (包含 360 道数学奥林匹克竞赛级别题目)上的 Pass@32 性能对比。横轴为不同模型表现,纵轴为模型性能(解决题目的百分比或者个数)
上图展示了 Goedel-Prover-V2 在 MiniF2F、PutnamBench 和 MathOlympiadBench 三个基准测试中的性能。所有数据在 Pass@32 下测得:
-
在三个数据集中,32B 旗舰模型在标准模式和自我修正模式下的性能均显著超过了之前的 SOTA 模型 DeepSeek-Prover-V2-671B 和 Kimina-Prover-72B。
-
在 MiniF2F 上,8B 模型的性能与模型尺寸大近 100 倍的 DeepSeek-Prover-V2-671B 相当。
PutnamBench 排行榜
下表为 PutnamBench 的最新排名。Goedel-Prover-V2-32B 在相对更少的计算开销(pass 数)下取得了领先成绩。

表 1: PutnamBench 排行榜。
推理时的计算扩展性
推理时的计算扩展性曲线显示,在不同的推理采样预算下,Goedel-Prover-V2-32B 模型的性能均稳定超过了之前的同类模型。
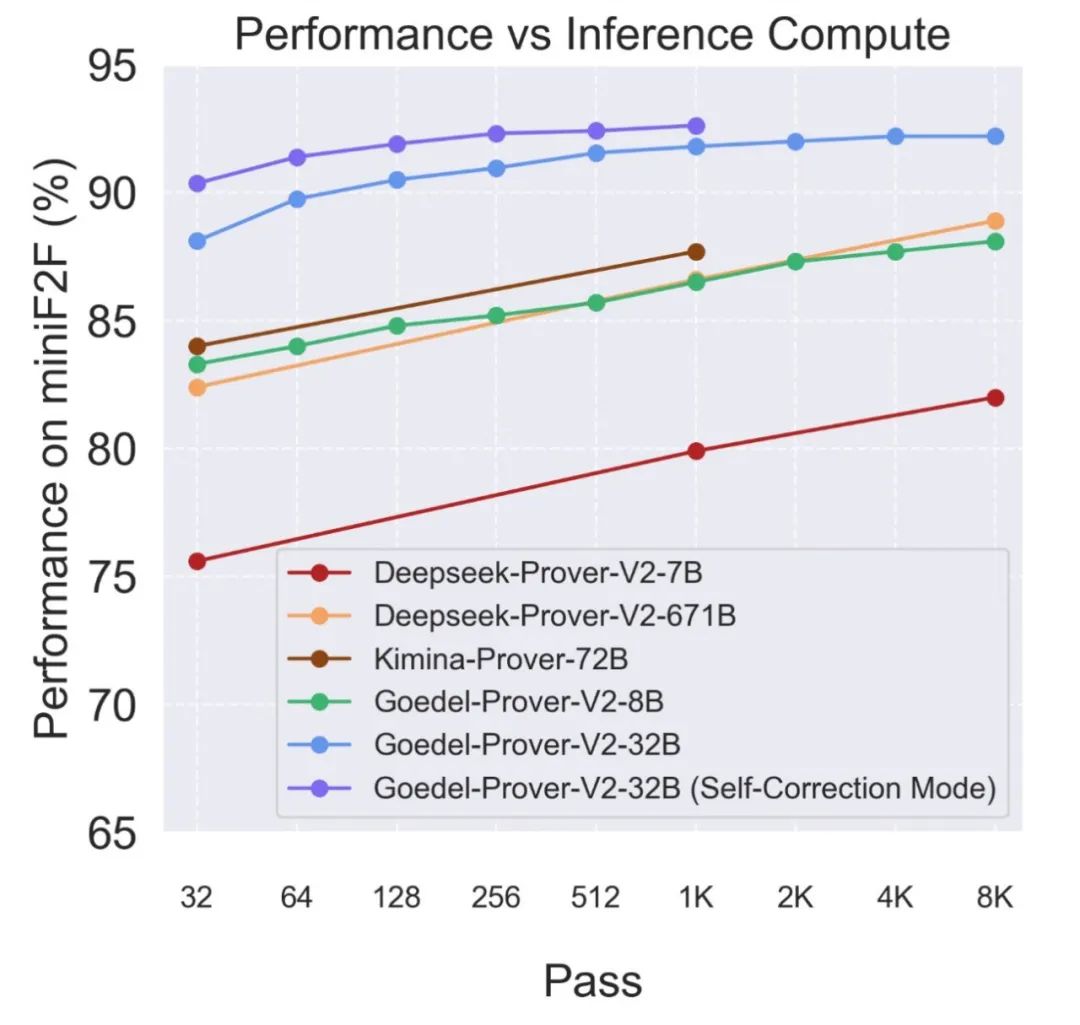
图 2: 在不同采样预算下,模型在 MiniF2F 测试集上的性能表现。横轴为 pass 数(采样预算),纵轴为解决题目的百分比
技术方法
Goedel-Prover-V2 的性能主要基于以下四种核心技术:
-
专家迭代与强化学习 (Expert Iteration & RL):项目遵循标准的训练流程:形式化问题、生成并验证证明、利用新证明训练下一代模型,并结合强化学习进行优化。
-
分层式数据合成 (Scafforded Data Synthesis):该技术自动生成中等难度的问题,用以弥合已解决的简单问题与尚未解决的复杂问题之间的鸿沟,从而实现更平滑的难度递进,并为模型提供更密集且更具信息量的训练信号。
-
验证器引导的自我修正 (Verifier-Guided Self-Correction):模型被训练以使用 Lean 编译器的反馈来迭代修正自身证明,这一能力被整合到监督微调和强化学习流程中。
-
模型平均 (Model Averaging):为避免训练后期模型多样性下降,研究者将训练好的模型与基础模型进行权重平均,此方法有助于提升在需要更多采样次数时的 Pass@K 性能。
模型与数据集下载
为了促进相关领域的研究,团队已公开发布了 Goedel-Prover-V2 模型及全新的 MathOlympiadBench 基准。
模型下载
-
Goedel-Prover-V2-32B:
https://huggingface.co/Goedel-LM/Goedel-Prover-V2-32B
-
Goedel-Prover-V2-8B:
https://huggingface.co/Goedel-LM/Goedel-Prover-V2-8B
数据集下载
-
MathOlympiadBench:
https://huggingface.co/datasets/Goedel-LM/FoMOBench
MathOlympiadBench 是一个收录了奥林匹克级别数学竞赛问题形式化版本的数据集,来源包括 Compfiles 和 IMOSLLean4 等代码库。数据集共包含 360 个问题,覆盖了 IMO (International Math Olympiad,国际数学奥林匹克竞赛)、IMO 候选短名单及其他区域性竞赛题。
研究团队表示,发布此模型旨在支持开源社区的研究,包括为 IMO 等数学竞赛做准备的相关项目。包含完整技术细节的论文将在未来几周内发布。
项目骨干:

林勇(Yong Lin),普林斯顿大学博士后,与金驰、陈丹琦、Sanjeev Arora 教授合作,研究方向为大模型的形式化数学推理与后训练。相关成果曾获 NAACL 杰出论文奖,入选 2023 年苹果 AI 学者。
个人主页:

唐山茖(Shange Tang),普林斯顿大学博士生,导师是金驰和范剑青教授。他的研究领域包括大模型的形式化数学推理、分布外泛化等。
个人主页:
项目负责人:

金驰(Chi Jin),普林斯顿大学电子与计算机工程系教授。他的研究专注于机器学习的决策制定,致力于开发具备复杂决策与高级推理能力的智能体。其团队在强化学习、博弈论及最优化等领域奠定了坚实的理论基础。近期,他们正积极将研究拓展至大语言模型(LLM),重点提升其推理能力。金驰教授曾荣获多项重要荣誉,如斯隆研究学者奖(Sloan Research Fellowship)、美国国家科学基金会 CAREER 奖(NSF CAREER Award)等。
个人主页:

©
(文:机器之心)