
大模型

智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区

智谱总裁王绍兰介绍了公司最新的开源模型进展,并宣布出资3亿元支持全球AI开源社区发展。智谱近期开源了GLM-Z1-Air、GLM-Z1-Air和GLM-Z1-Rumination三款模型,涵盖9B与32B参数大小,已在新域名z.ai上开放C端体验。

这本书为啥全网都在追?我看了3页就明白了!
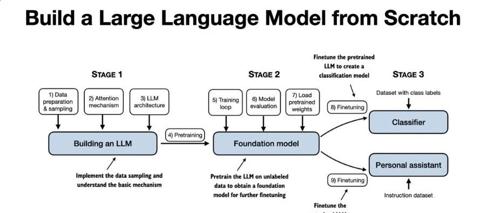
Sebastian Raschka 的《从零构建大模型》是一本帮助读者理解并实战大模型开发的书。通过直接、清晰的教学方式,本书涵盖了从数据准备到模型部署的全流程,适合Python基础和普通笔记本硬件条件的开发者。
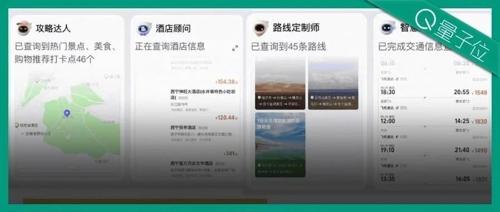
聚焦个性化学习,夸克不想做一个千篇一律的“AI+教育”
教育作为大模型天然的应用场景之一,在AI+教育赛道上竞争激烈。夸克学习产品聚焦个性化需求,并通过AI技术提升用户体验,形成以‘AI超级框’为核心入口的学习产品,旨在推动学习场景中的通用能力变革。

DeepSeek多模态能力起底!一探究竟Janus 系列模型:解耦统一多模态理解和生成模型的视觉编码

解统一架构代表作 Janus 以及后续扩大版本 Janus-Pro。
>>加入极市CV技术交流群,走
AIGC最强参考!2025值得关注AIGC企业&产品榜单揭晓

第三届中国AIGC产业峰会上,58家企业和53项产品入选2025年值得关注的AIGC榜单,涵盖大模型、基础模型、行业应用等全产业链,推动AIGC技术在企业运营中的实际应用。