
无需昂贵设备,单目方案生成超逼真3D头像,清华&IDEA新研究入选CVPR2025

清华和IDEA的研究团队提出HRAvatar,一种基于3D高斯点的单目视频重建方法,实现灵活且精确的几何变形、表情编码器提升表情参数提取准确性,并通过分解外观属性(反照率、粗糙度、菲涅尔反射)实现真实重光照。
清华和IDEA的研究团队提出HRAvatar,一种基于3D高斯点的单目视频重建方法,实现灵活且精确的几何变形、表情编码器提升表情参数提取准确性,并通过分解外观属性(反照率、粗糙度、菲涅尔反射)实现真实重光照。
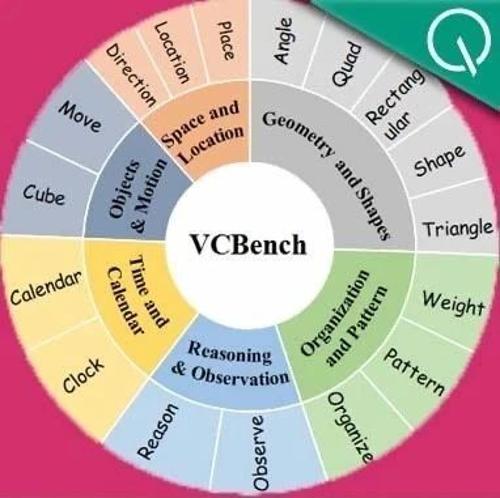
大模型在小学数学题测试中表现不佳,平均得分为47.03%-49.77%,显著低于人类的93.30%。达摩院推出的新基准VCBench专注于评估具备显式视觉依赖性的多模态数学推理任务,强调vision-centric而非knowledge-centric。该基准主要针对小学1-6年级的数学问题,全面评估纯视觉推理的多种能力,涵盖六大核心认知领域和五种不同认知能力。

小米自研芯片玄戒 O1 引发关注,与高通旗舰芯片对比测试。跑分成绩优异,但在实际应用中表现略逊一筹。总体而言,玄戒 O1 为小米在高端市场提供了新的选择。

字节跳动开源文档解析模型Dolphin,相比同类大模型提升2倍解析效率。其采用两阶段解析方法,先解析结构后内容,性能超越GPT-4.1等通用多模态和垂类OCR模型。

Hedra通过生成超写实AI角色推动视频内容,完成3200万美元A轮融资。公司宣称其核心技术‘全模态基础模型’能创造逼真的数字角色,尤其在播客场景下表现出色。




