

Dolphin团队 投稿
量子位 | 公众号 QbitAI
字节跳动刚刚开源一款全新文档解析模型——Dolphin。
与目前市面上各类大模型相比,这款轻量级模型不仅体积小、速度快,并且取得了令人惊艳的性能突破,解析效率提升近2倍。
测试结果显示,Dolphin在文档解析任务上解析准确率超越了GPT-4.1、Claude3.5-Sonnet、Gemini2.5-pro、Qwen2.5-VL等通用多模态大模型,以及最近推出的号称最强OCR大模型的Mistral-OCR等垂类大模型。

论文已被收录于ACL 2025,项目链接可见文末。
突破性的两阶段解析方法
文档图像解析解决方案可以分为两大流派:集成式方法以及端到端方法。
集成式方法在链路中组装多个专家模型,端到端方法则利用视觉语言模型通过自回归解码直接生成结构化结果。
而Dolphin采用了全新的“先解析结构后解析内容”(analyze-then-parse)两阶段范式:
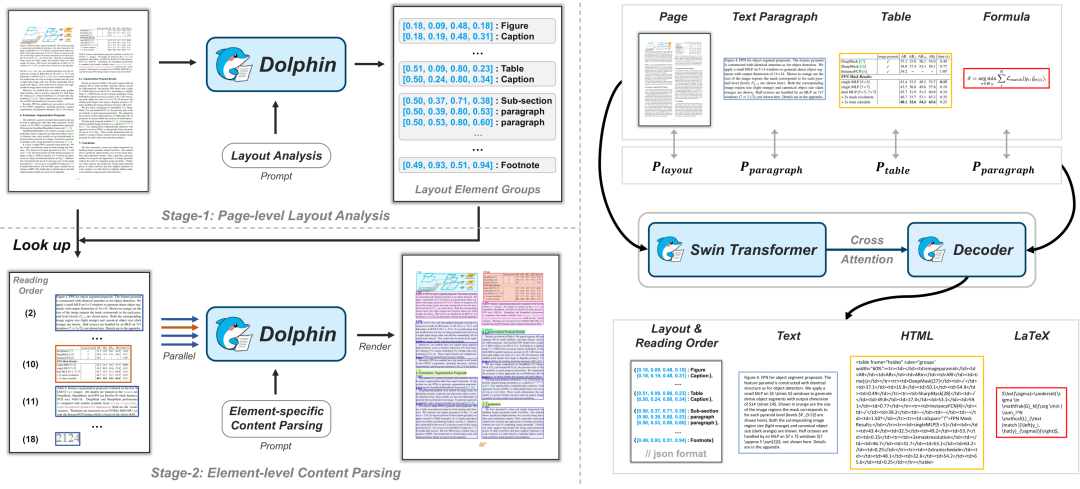
△Dolphin遵循一种基于编码器-解码器Transformer架构的分析-解析范式
-
第一阶段—文档布局解析:按照自然阅读顺序生成文档元素序列,即每个文档元素的类别及其坐标。这里的文档元素值得是标题、图表、表格、脚注等。 -
第二阶段—元素内容解析:使用这些元素作为”锚点”,配合特定提示词实现并行内容识别,从而完成整页文档的内容提取。
这种创新架构一箭双雕,既避免了传统商用方案中多OCR专家模型级联带来的错误累积问题,又克服了通用多模态大模型易丢失版面结构信息、自回归解码效率低的痛点。
因为获取孤立的元素图像(例如表格、公式)及其标注比收集包含多种元素的完整文档页面更可行,Dolphin的元素解耦解析策略在数据收集方面提供了独特的优势。
更轻量、更高效
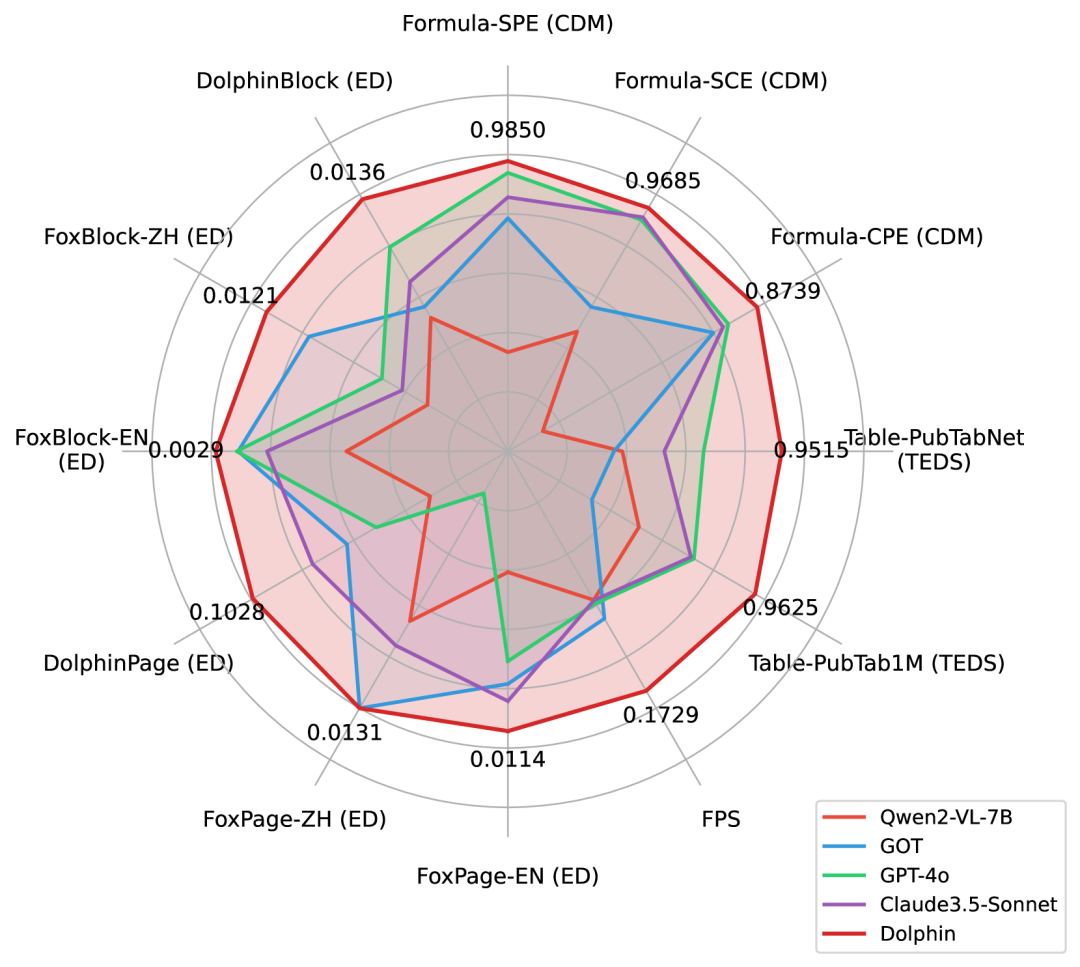
△Dolphin与先进VLMs在基准测试中的比较
对于流行的基准测试,Dolphin在多种页面级和元素级解析任务中达到了最先进的性能。
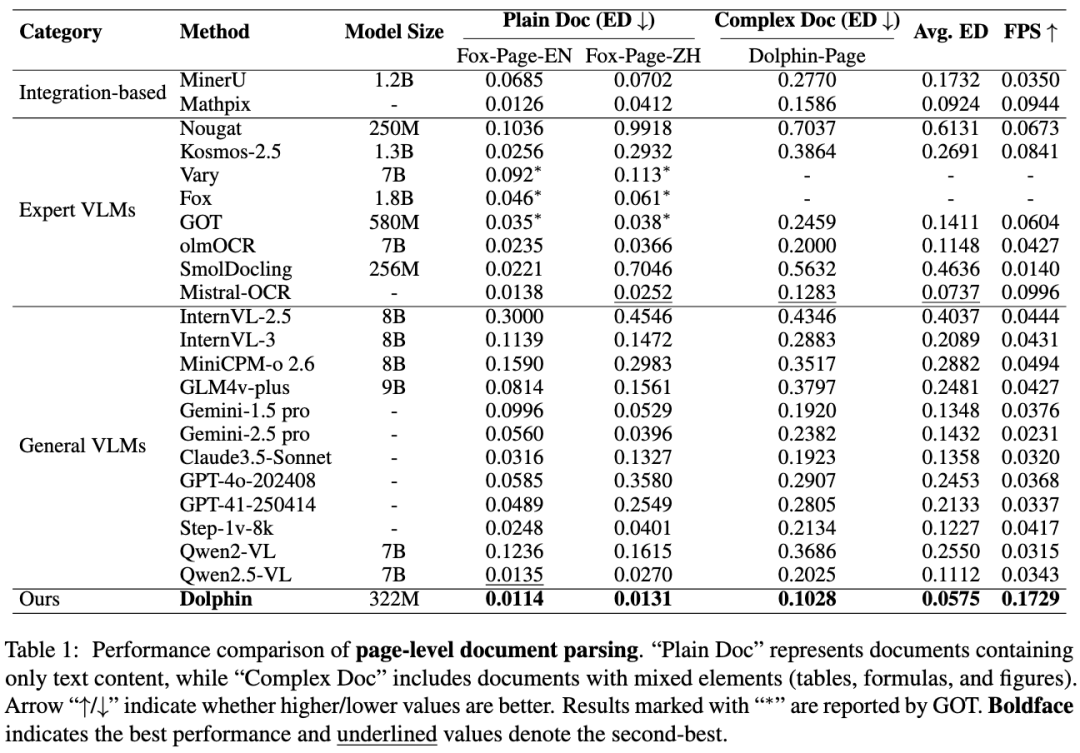 △页面级文档解析的性能比较
△页面级文档解析的性能比较
尽管Dolphin具有轻量级架构(322M参数),但其性能优于基于集成的方法和更大的VLM。
“Plain Doc”代表仅包含文本内容的文档,而“Complex Doc”包括包含混合元素(表格、公式和图形)的文档。
对于纯文本文档,Dolphin在英文和中文测试集上分别达到了0.0114和0.0131的编辑距离,优于垂类的VLM如GOT(编辑距离为0.035和0.038)和通用VLM如GPT-4.1(编辑距离为0.0489和0.2549)。
在处理包含表格、公式、图像等混合元素的文档时,Dolphin达到了0.1283的编辑距离,优于所有基线。
此外,凭借并行解析设计,Dolphin展示了显著的效率提升,达到了0.1729FPS,比最有效的基线(Mathpix,0.0944FPS)快近2倍。
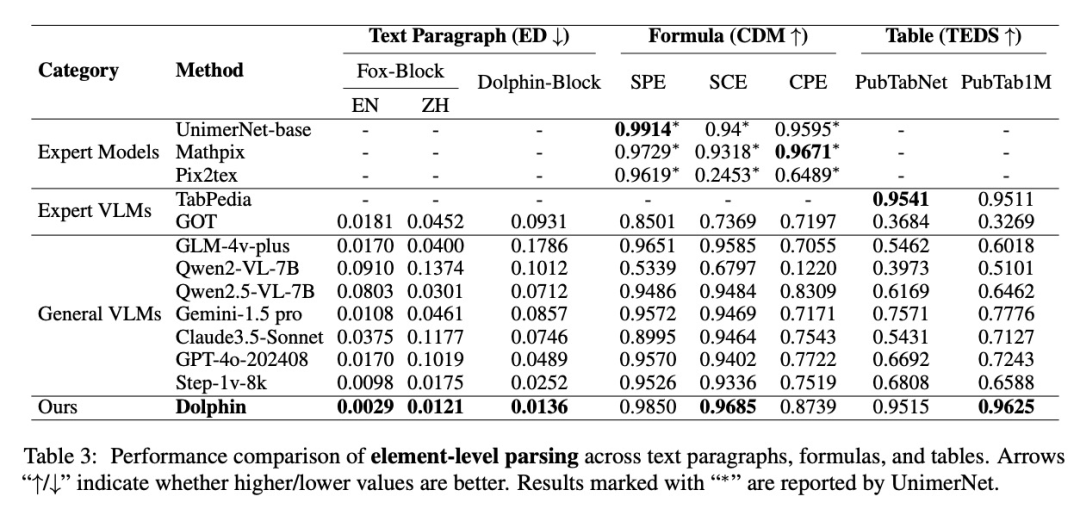
△文本段落、公式和表格的元素级解析性能比较
对于文本段落解析,Dolphin在Fox-Block和Dolphin-Block测试集上都取得了具有竞争力的结果。
在公式识别方面,Dolphin在不同复杂度级别(SPE、SCE和CPE)上都展现出强大的能力,取得了与专业公式识别方法相当的具有竞争力的CDM分数。
对于表格解析,Dolphin在PubTabNet和PubTab1M基准测试上显示出有前景的结果,有效地捕捉了结构关系和单元格内容。
在文本段落、公式和表格上这些持续强劲的结果展示了Dolphin在基础识别任务中的具有竞争力的性能。
实际案例展示
下面通过几个实际案例,直观展示Dolphin的文档解析能力:
无论是多栏学术论文、复杂公式、中英表格,Dolphin都能精准识别、高效处理。

△Dolphin的页面级解析结果可视化
-
左:第一阶段布局分析,包含预测的元素边界和阅读顺序。 -
中:第二阶段特定元素的解析输出。 -
右:最终以markdown格式渲染的文档。

△Dolphin在各种场景下的元素级解析演示
顶部行显示输入图像,底部行显示相应的识别结果。
-
左:复杂布局中的文本段落解析。 -
中:双语文本段落识别。 -
右:复杂表格解析(显示渲染结果)。

△Dolphin的其他功能
-
左:从给定的边界框区域中解析文本内容。 -
右:文本识别结果,显示了检测到的文本行(在图像中可视化)及其内容。
Hugging Face:https://huggingface.co/ByteDance/Dolphin
论文:https://arxiv.org/abs/2505.14059
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)