
无需预对齐即可消除批次效应,东京大学团队开发深度学习框架STAIG,揭示肿瘤微环境中的详细基因信息

团队提出了一种名为 STAIG (基于图像辅助的图对比学习进行空间转录组学分析)的深度学习框架,能够
团队提出了一种名为 STAIG (基于图像辅助的图对比学习进行空间转录组学分析)的深度学习框架,能够
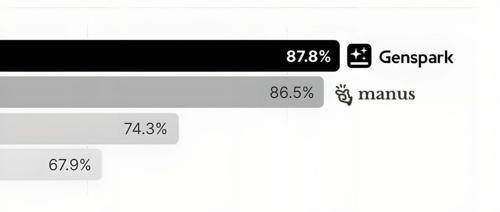
Genspark 推出了通用 Super Agent,并在GAIA Benchmark上超越了Manus。其功能包括旅游规划、短视频生成和视频转PPT等。不过价格不菲且交互设计有待改进。未来通用Agent市场将更加繁荣。

PaperBench 是由 OpenAI 开发的一个基准测试,用于评估 AI Agent 复现尖端 AI 研究的能力,共包含 8,316 个任务,并通过评分标准进行自动化评估。

Dolphin 是由 Dataocean AI 和清华大学合作开发的多语言语音识别模型,支持40种东方语言和22种汉语方言。它在210,000小时的数据上训练完成,包含专用数据集和开源数据集。该模型能执行语音识别、VAD、分割和LID任务。
Genspark超级智能体发布,能够在无需编程的情况下执行复杂任务,包括制作做饭视频和创建HTML游戏。其背后公司MainFunc由前百度高管景鲲创立,展示了从AI搜索转向智能体的新方向。

星海图近期完成A2和A3轮融资,总融资额超3亿元人民币,由凯辉基金领投,IDG资本、高瓴创投等多家机构参投。公司专注于具身智能机器人研发,已完成多轮技术突破与硬件能力构建。
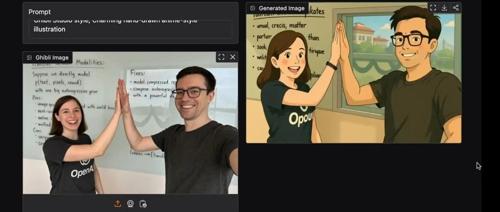
EasyControl_Ghibli是一款免费且易于使用的AI模型,生成吉卜力风格图像。AudioX是统一的扩散Transformer模型,支持多种模态输入和自然语言控制。Serena是一个免费代码助手集成LLM功能。uniOCR是通用Rust OCR引擎,提供本地及云服务。MCP Server for Milvus为LLM应用提供Milvus向量数据库访问桥梁。

V²Flow团队发布的新开源框架V²Flow解决了视觉Token与大语言模型词表的不一致问题,实现了高保真自回归图像生成。该技术通过视觉词汇重采样器将视觉内容嵌入到LLM的词汇空间中,并使用掩码自回归流匹配解码器进行视觉重建,显著提高了压缩效率和生成质量。

CalibQuant团队在InternVL-2.5模型上提出了一种1比特量化方法,通过校准策略缓解了低比特数量化带来的失真问题。实验结果显示,在多种任务和内存限制下,该方法相比基线有显著的性能提升。

OpenAI发布PaperBench新基准测试,最新版Claude-3.5-Sonnet在复现ICML2024论文任务中超越其他顶尖大模型。对比去年的MLE-Benchmark,PaperBench更侧重综合能力评估。