
Dolphin

字节开源多模态复杂文档解析模型!Dolphin:页面与元素并行解析,精准解析复杂文档!

字节跳动开源多模态AI模型Dolphin,通过两阶段机制精准解析复杂文档,支持页面级和元素级解析,并提供在线Demo及本地部署指南。
字节Dolphin:多模态文档图像解析模型
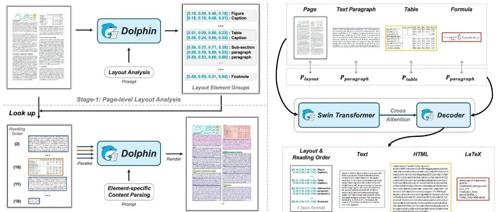
Dolphin 是一种新颖的多模态文档图像解析模型,采用‘分析后解析’范式,通过两阶段方法高效处理文本段落、图表、公式和表格等交织内容,实现了卓越的解析效率。
字节开源高效解析文档图像的新型多模态模型Dolphin,快速将复杂的文档图像转化为结构化数据。
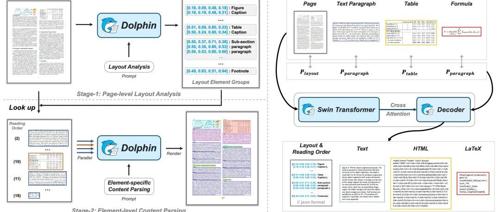
Dolphin是基于单一视觉语言模型的两阶段文档图像解析模型,采用自然阅读顺序生成元素序列和异构锚点提示进行高效并行解析。支持页面级和元素级解析,性能卓越。
「文档处理终结者」字节跳动Dolphin开源:从合同到试卷全搞定,多语言OCR+智能排版还原,B端企业刚需

发等场景,都需要高效、准确地从文档中提取和解析信息。然而,
传统的文档解析方法往往面临着诸多挑战,例
RAG技术于视频文章生成及东方语种+汉语方言识别Dolphin实现思路解析

2025年4月3日,北京天气晴朗。《Large Language Models Pass the Turing Test》评测了四个系统的表现,发现添加人设提示可以显著提升AI模型被误认为人类的比例。关于RAG和语音识别技术,文章介绍了WIKIVIDEO视频文章生成方案及面向东方语言的Dolphin语音大模型开源方案。
支持40种东方语言和22种汉语方言!清华大学开源自动语音识别模型Dolphin

Dolphin 是由 Dataocean AI 和清华大学合作开发的多语言语音识别模型,支持40种东方语言和22种汉语方言。它在210,000小时的数据上训练完成,包含专用数据集和开源数据集。该模型能执行语音识别、VAD、分割和LID任务。