
ChatGPT、Grok、Manus 都在卷的新功能:AI 定时任务是真香吗?
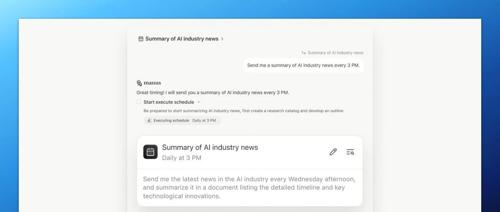
定时任务功能已成为 AI 工具标配,Manus 定时任务发布于 6 月 13 日,支持设定执行频率、多步骤串联等流程控制。
大语言模型
定时任务功能已成为 AI 工具标配,Manus 定时任务发布于 6 月 13 日,支持设定执行频率、多步骤串联等流程控制。

多模态统一嵌入框架UNITE通过Modal-Aware Masked Contrastive Learning解决跨模态干扰,显著提升细粒度检索、指令检索等多个任务性能。

近日,中山大学计算机学院与腾讯微信搜索团队联合提出 Q-RM(Q-function Reward Model),在 ICML 2025 正式发表。这一方法专注于构建更精确的 token-level 奖励信号,显著提升了大语言模型的训练效率和效果。

2025年6月24日,北京晴天。文章讨论了信息抽取和RAG落地中的引文生成、来源定位需求及其底层逻辑与实际案例。提及模型可能产生“幻觉”导致的误导性答案,通过引文标注来源增强可信度。此外,文章总结了2025年RAG的发展趋势,包括多模态文档解析与统一抽取的重要性。

《人工智能大模型私有化部署技术实施与评价指南》是国内首部针对AI大模型私有化部署的标准,旨在解决企业因缺乏统一标准和评价系统导致的技术选型混乱、算力资源错配等问题。该标准涵盖选用、部署、优化全流程要点,强调技术实施、安全保密、质量评价及行业案例融合,并推动三方协作实现持续改进与优化。目前正面向起草单位及起草人征集参与。
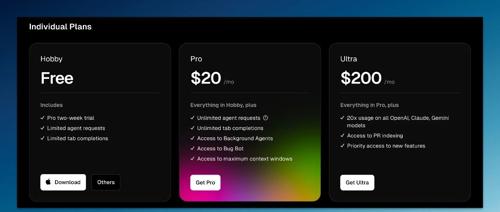
Cursor 推出 Ultra 订阅,定价 200 美元/月,包含更多高级功能。同时对 Pro 计划进行更新,默认限流。Pro 计划的用户可以选择恢复原版 ‘500 次快速请求’ 的设置。

今日特别推荐V2.3 ULTRA版本,提升整体输出效果并带来更自然且平衡的光影效果、强化皮肤细节及真实感。包括赛博皮衣女孩、紫色头发少女、蒙眼女子等多款模型。

论文提出CMCRL框架解决放射学报告生成任务中的挑战,包括长序列文本生成、病灶定位和视觉-语言偏倚问题。通过两阶段设计有效捕捉并校正跨模态数据中的偏倚,显著提高准确率和临床可信度。

