
 量子位
量子位

一招缓解LLM偏科!调整训练集组成,“秘方”在此 上交大&上海AI Lab等

上海交通大学及上海AI Lab联合团队提出IDEAL方法,通过调整SFT训练集的组成来提升LLM在多种领域上的综合性能。研究发现增加训练数据数量并不一定提高模型整体表现,反而可能导致“偏科”。
不是视频模型“学习”慢,而是LLM走捷径|18万引大牛Sergey Levine

UC伯克利大学计算机副教授Sergey Levine提出问题:语言模型能从预测下一个词中学习很多,但视频模型却从预测下一帧中学到很少。通过类比柏拉图洞穴的故事,他讨论了AI在认知和学习能力方面存在的缺陷,并认为语言模型可能只是对人类智慧的逆向工程,而非真正的自主探索。

强化学习之父:LLM主导只是暂时,扩展计算才是正解

新晋图灵奖得主Richard Sutton预测大模型主导是暂时的,未来五年甚至十年内AI和强化学习将转向通过Agent与世界的第一人称交互获取‘体验数据’的学习。他强调AI需要新的数据来源,并且要随着增强而改进。他认为真正的突破还是来自规模计算。
6分钟狂掉750亿市值!苹果发布会发啥了…
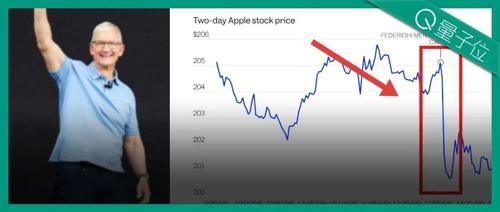
苹果WWDC大会因Siri更新推迟引发股价暴跌750亿美元。发布会聚焦液态玻璃设计、全系操作系统功能更新及AI能力的集成,但开发者反馈冷淡。苹果强调AI战略地位,但仍面临与OpenAI合作等挑战。

首创像素空间推理,7B模型领先GPT-4o,让VLM能像人类一样「眼脑并用」

研究团队提出像素空间推理范式,让视觉语言模型具备原生视觉操作能力,打破文本对视觉语义的翻译牢笼。通过视觉主动操作和视觉主导推理实现高效视觉理解,在高清图像、复杂场景计数及长视频推理中均取得显著性能提升。
