Who’sAdam?最逆天的NeurIPS评审出炉了

MLNLP社区是国内外知名的人工智能与自然语言处理学术社区,旨在促进学者、企业和爱好者的交流合作。NeurIPS 2025评审出现了严重的拼写错误引起热议,AI在审稿中的应用愈发普遍。
MLNLP社区是国内外知名的人工智能与自然语言处理学术社区,旨在促进学者、企业和爱好者的交流合作。NeurIPS 2025评审出现了严重的拼写错误引起热议,AI在审稿中的应用愈发普遍。

MLNLP社区致力于推动国内外机器学习与自然语言处理领域的交流合作。社区举办 ‘大语言模型智能体社会模拟’ Workshop,征稿启事公布,邀请相关领域学者参与研讨。
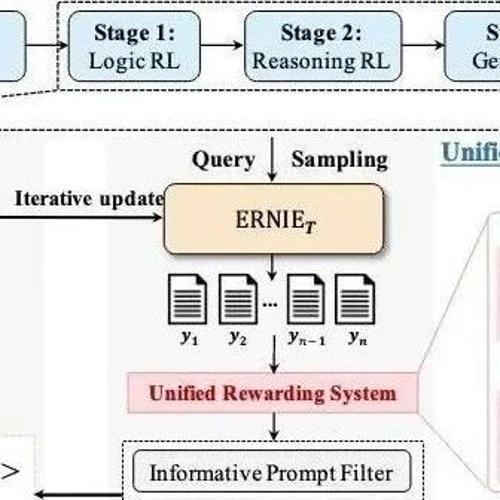
MLNLP社区致力于促进国内外机器学习与自然语言处理的交流与发展,涵盖硕博生、高校老师及企业研究人员。文心4.5开源10个多模态大模型,并介绍其后训练阶段的技术细节。
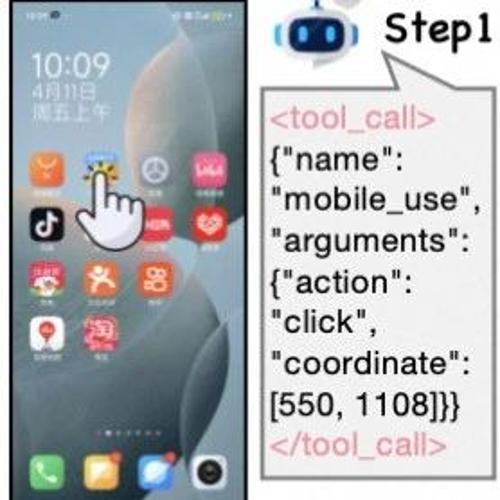
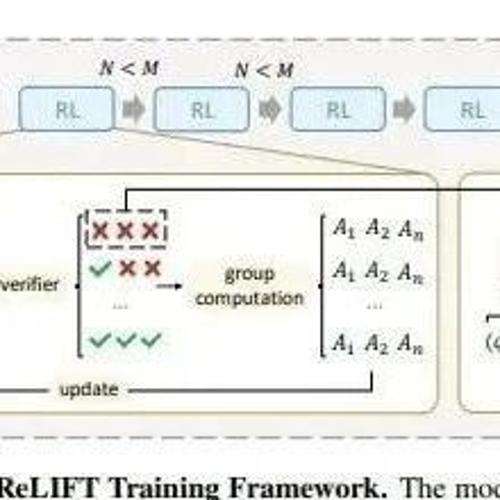
MLNLP社区介绍了采用多回合、任务导向的交互式强化学习框架Mobile-R1,旨在提高移动代理在复杂环境中的适应性和探索能力,并提出三阶段训练流程提升模型表现。团队通过高质量轨迹数据集进行格式微调、动作级和任务级训练,最终显著提升了模型在多种基准上的性能。

MLNLP社区发布ICCV 2025论文《Beyond Walking》:提出大规模图像-文本行人异常检索基准集,融合AI生成图像、大模型描述与专家修正,解决行为数据稀缺问题,提升识别精度至84.93%。

MLNLP社区是国内外知名的人工智能学术社区,致力于推动跨领域的交流合作。Mistral AI发布多个开源模型,并升级其对话式AI助手Le Chat,新增功能如深度研究模式、语音模式、原生多语言推理等,使Le Chat在应用层面与ChatGPT竞争。