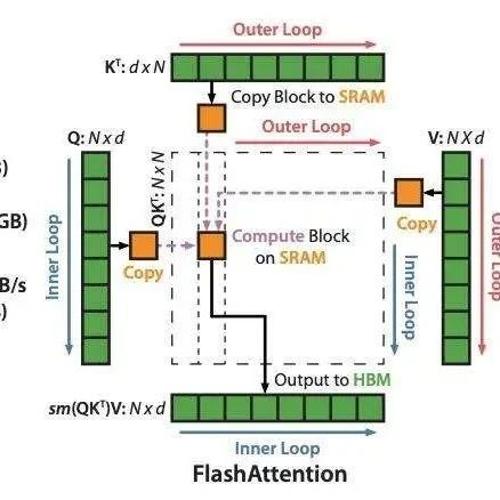
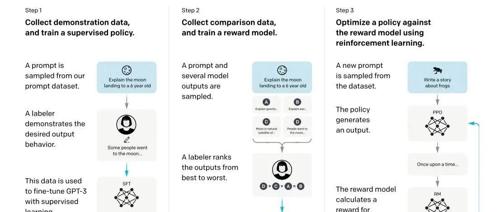
极市干货
极市干货

CVPR 2025 加快22倍!Meta提出EdgeTAM:基于SAM 2的高效视频分割模型,性能与速度兼得!

提出了EdgeTAM,这是一个基于SAM 2的高效视频分割模型。EdgeTAM通过引入2D空间感知器



CVPR 2025 满分论文|清华提出TSP3D:基于语言引导空间剪枝的高效3D视觉Grounding

名为 TSP3D 的高效 3D 视觉定位框架,通过语言引导的空间剪枝和多层稀疏卷积架构,实现了高精度