

长话短说
OpenAI 发布了 ChatGPT Agent:OpenAI 版的 Manus
集成在了ChatGPT,付费会员(Pro/Plus/企业用户)可用
下面是本次发布会的具体内容,整理如下
ChatGPT Agent 发布会实录

开场:Agent 的诞生
发布会由 Sam Altman 开场。
他回顾了之前发布的 Deep Research 和 Operator,指出用户真正的需求是希望将这些强大的能力整合起来,形成一个统一的、能使用电脑完成复杂、长周期真实世界任务的 AI 智能体。
为此,OpenAI 整合了 Operator 和 Deep Research 团队,共同打造了今天的主角——ChatGPT Agent。

核心能力
ChatGPT Agent 的核心是拥有一个自己的虚拟电脑环境,并配备了各种工具
浏览器(Browser)
包含文本和视觉两种模式。文本模式(类似 Deep Research)可以高效抓取信息,而视觉模式(类似 Operator)能像人一样点击、拖拽,与复杂的网页 UI 交互
终端(Terminal)
允许 Agent 运行代码、生成和分析文件(如 Excel 表格、PPT 幻灯片),甚至调用外部 API
API 连接
Agent 可以连接到公共 API,也可以通过连接器安全地访问用户的私有数据源,如 Google Drive、GitHub 等
图像生成
集成了图像生成能力,可以为报告或幻灯片创建视觉素材
功能演示:复杂的婚礼策划
团队展示了一个非常贴近生活的复杂任务:帮助朋友策划婚礼行程。
任务下达
用户提供了一个婚礼网站链接,要求 Agent 推荐符合着装要求的服装、寻找酒店并挑选礼物。
执行过程
Agent 首先访问婚礼网站,提取关键信息(日期、地点、着装要求)。接着,它搜索天气信息,并根据温暖气候推荐了合适的服装选项。然后,它在 Booking.com 上搜索并比较了附近的酒店。最后,它还搜索了合适的结婚礼物建议。
结果交付
Agent 生成了一份详细的《婚礼准备报告》,清晰地列出了活动概览、服装推荐、酒店选项和礼物建议,所有信息都有来源链接和截图作为佐证。

在生成的过程中,可以追加任务,如“为我们团队的启动仪式制作一些 swag 贴纸,并从 StickerMule 订购 500-575 张。”
Agent 立即理解了新指令,开始利用图像生成工具设计贴纸,并访问 StickerMule 网站准备下单。

功能演示二:Agent 评估自己
为了展示 Agent 处理数据和生成文件的能力,团队进行了一个“元任务”(meta-task):让 Agent 评估自己的性能。
任务
“从 Google Drive 连接器中拉取 ChatGPT Agent 的评测数据,并制作成带图表的幻灯片。不需要引言和结论,只呈现带图表的结果。”
执行
Agent 通过 API 连接到 Google Drive,找到了评测数据文件。接着,它使用终端(Terminal)编写并运行代码,处理数据、生成图表,并最终将所有内容整合到一个 PowerPoint(.pptx)文件中。
结果
Agent 成功生成了一份专业的幻灯片,其中包含了多个基准测试的对比图表。
性能基准
ChatGPT Agent 在基准测试中得到了验证,超越了以往模型。其在多个领域接近甚至超越了人类专家的。
高难度智能测试
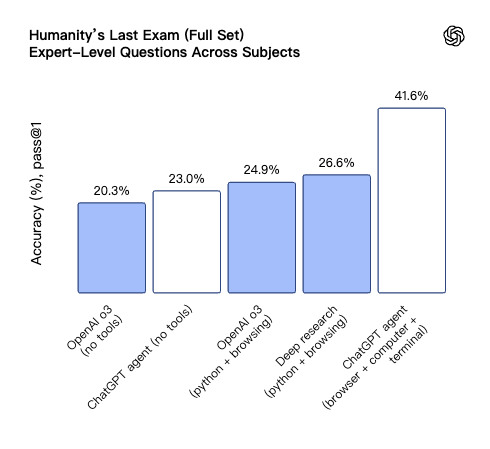
Humanity’s Last Exam (HLE) 是一个衡量 AI 在各学科专家级问题上表现的综合性测试。Agent 模式凭借其动态规划和自主选择工具的能力,取得了 41.6% 的新 SOTA 成绩。
更有趣的是,当采用“学习小组”策略(并行运行 8 次,选择置信度最高的答案)时,分数进一步提升至 44.4%。
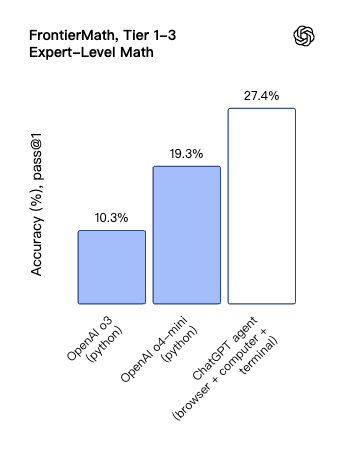
FrontierMath 是在目前已知的最难数学基准测试,包含了人类专家都需要数小时甚至数天才能解决的新问题,ChatGPT Agent 利用代码执行等工具,取得了 27.4% 的准确率,远超之前的模型。
真实世界任务基准
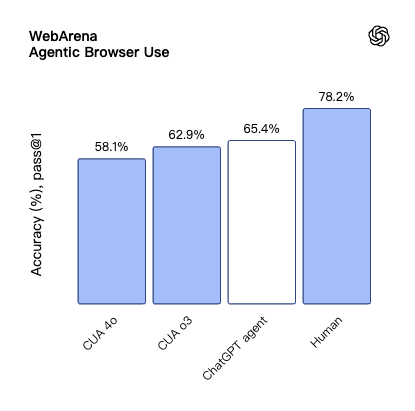
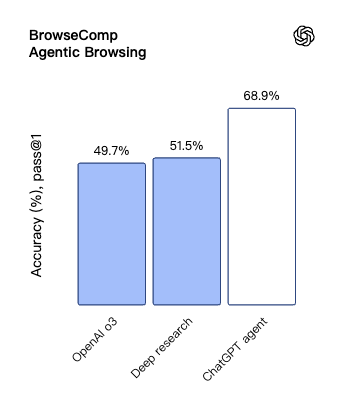
WebArena 和 BrowseComp 两个基准测试专注于评估 Agent 的网页浏览和信息检索能力。在 WebArena 上,Agent 模式超越了 o3 驱动的 CUA 模型;在 BrowseComp 上更是创下 68.9% 的新纪录,比 Deep Research 高出 17.4个百分点。
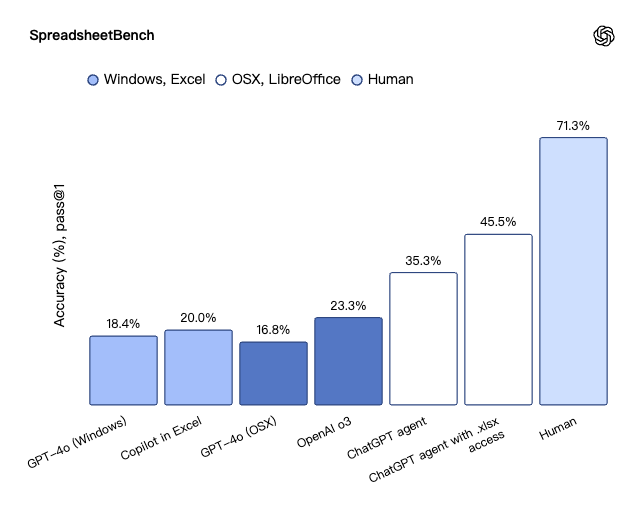
在模拟真实电子表格编辑任务的 SpreadsheetBench 中,ChatGPT Agent 的表现尤为突出。在能够直接访问和编辑 .xlsx 文件的情况下,其准确率高达 45.5%,远超 Copilot in Excel 的 20.0%,并已接近 71.3% 的人类水平。
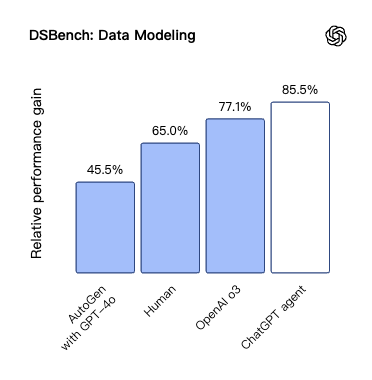
在 DSBench 数据科学基准测试中,Agent 的表现更是惊人,在数据分析和数据建模两个子任务上均大幅超越了人类专家的表现。
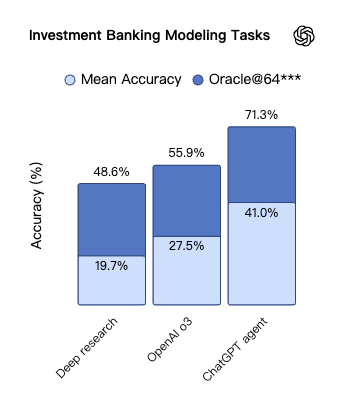
在一系列内部专业基准测试中,Agent 的能力同样得到了验证。
例如,在模拟投资银行分析师(Economically important tasks) 工作(如为财富 500 强公司制作三表模型)的测试中,Agent 的平均准确率高达 41%,显著高于 Deep research 和 o3。
在其他具有经济价值的复杂知识工作中,Agent 的产出在约一半的情况下与人类专家相当或更优。
安全措施
团队强调,Agent 是一项强大的新技术,但也带来了新的安全挑战,例如“提示词注入”(Prompt Injection)攻击。为此,OpenAI 采取了多层安全措施:
模型训练
训练模型忽略可疑或恶意的网页指令
流程监控
实时监控 Agent 的行为,发现异常时及时中止
用户确认
在执行关键操作(如支付、发送邮件)前,会请求用户确认
用户接管
用户可以随时点击“Take control”按钮,亲自接管浏览器完成敏感操作
上线计划:
Pro & Plus/Team 用户
即日开始逐步推出。
Pro 用户每月 400 次调用,Plus 和 Team 用户每月 40 次。
Enterprise & EDU 用户
预计本月底前上线
(文:赛博禅心)