
 GiantPandaCV
GiantPandaCV
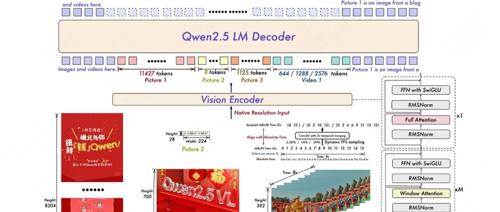



【博客转载】CUDA Kernel Execution Overlap

CUDA kernel执行重叠可以通过调整blocks_per_grid的值来实现。通过使用不同的blocks_per_grid值,可以观察到不同kernel执行之间的重叠效果。隐式同步可能导致默认流中的CUDA命令间的同步问题,并可通过启用per-thread default Stream来解决。
[Triton编程][基础]vLLM Triton Merge Attention States Kernel详解

7907703243110
编辑丨GiantPandaLLM
0x00 前言
本文介绍vLLM中Tr
MetaShuffling:Meta的Fused MoE kernel工程方案,更激进的Kernel优化和尽量避免Padding
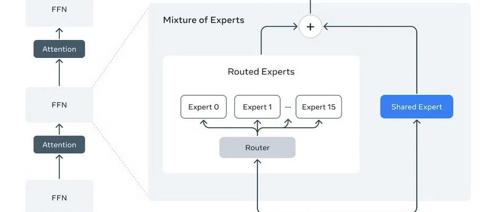
lerating-llama-4-moe-inference/
MetaShuffling: 加速L
[Triton编程][基础] Triton Fused Softmax Kernel详解: 从Python源码到PTX分析

562146477609112
编辑丨GiantPandaLLM
0x00 前言
Triton Fu