首个多模态统一CoT奖励模型来了,模型、数据集、训练脚本全开源

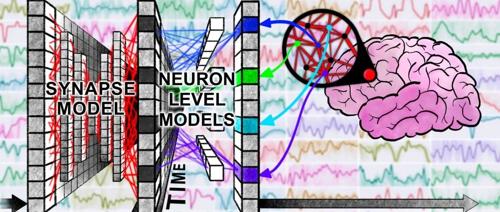
腾讯混元等联合提出的新模型UnifiedReward-Think能进行长链式推理,首次让奖励模型在视觉任务上真正 ‘学会思考’。该研究提出了三阶段训练框架,并展示了其在多个视觉任务中的出色表现和可靠性。
腾讯混元等联合提出的新模型UnifiedReward-Think能进行长链式推理,首次让奖励模型在视觉任务上真正 ‘学会思考’。该研究提出了三阶段训练框架,并展示了其在多个视觉任务中的出色表现和可靠性。
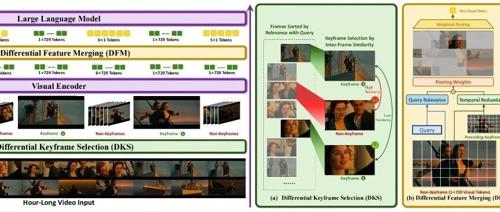
蚂蚁和中国人民大学的研究团队提出ViLAMP模型,实现对超长视频的高效处理。ViLAMP通过混合精度策略,在关键帧上保持高精度分析,大幅提升了视频理解效率,并在多个基准测试中超越现有方案。

本文提出了一种无需微调的通用图像定制方法——多主体协同注意力控制(MCA-Ctrl),通过扩散模型实现精确的背景和布局控制,解决了现有技术方案中的关键瓶颈。

CoRT(Chain-of-Recursive-Thoughts)结合递归思考与自我批判,提升语言模型推理能力。两周内GitHub星标数突破2k。

本周解读机器之心PRO会员通讯第19期,涵盖2项专题解析及29项AI&Robotics要事速递。重点讨论了Native多模态模型的训练过程差异以及早融合晚融合的优劣。

近期,可灵研究团队推出的CineMaster电影级文本到视频生成框架允许用户通过3D感知控制目标和相机运动来创作高质量视频内容。该方法在SIGGRAPH 2025会议中被收录,并展示了从任意视频中提取3D控制信号的数据构建流程。
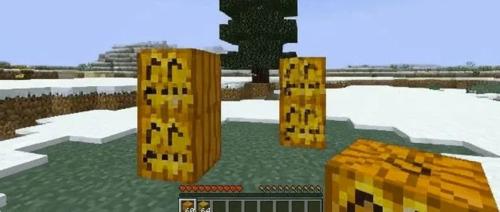
本文介绍了一种名为WorldMem的世界生成模型,通过引入记忆机制解决了上下文时间窗口受限导致的一致性问题,在Minecraft数据集上进行验证并展示良好效果。