

本文一作为肖泽琪,本科毕业于浙江大学,现为南洋理工大学博士生,研究方向是基于视频生成模型的世界生成和模拟,导师为潘新钢。个人主页:
https://xizaoqu.github.io
近年来,基于视频生成模型的可交互世界生成引发了广泛关注。尽管现有方法在生成质量和交互能力上取得了显著进展,但由于上下文时间窗口受限,生成的世界在长时序下严重缺乏一致性。
针对这一问题,南洋理工大学 S-Lab、北京大学与上海 AI Lab 的研究者提出了创新性的世界生成模型——WorldMem,通过引入记忆机制,实现了长时序一致的世界生成。
WorldMem 在 Minecraft 数据集上进行了大规模训练,支持在多样化场景中自由探索和动态变化,并在真实数据集上验证了方法的可行性。

-
论文名称:WorldMem: Long-term Consistent World Simulation with Memory
-
项目主页: https://xizaoqu.github.io/worldmem
-
论文代码:https://github.com/xizaoqu/WorldMem
-
Demo:https://huggingface.co/spaces/yslan/worldmem
研究背景
世界生成模型在近期受到了广泛关注,如谷歌的 Genie 2 [1]、阿里的 The Matrix [2]、Meta 的 Navigation World Models [4] 等。这些方法在生成质量与交互性方面取得了显著进展,但长时一致性问题仍未得到有效解决。
举例:当我们控制视角先向右转,再向左转。
在传统方法中,回看时场景内容会发生显著变化。

在 WorldMem 中,我们在世界生成模型中引入记忆机制,实现了一致的世界生成。

方法效果
WorldMem 通过引入记忆机制,实现了长时序下世界生成的一致性。智能体可在广阔的动作空间中探索多样场景,生成结果在视角和位置变化后仍保持良好的几何一致性。

同时,WorldMem 还支持时间一致性建模。比如在雪地中放置南瓜灯,随着时间推移,模型不仅保留该物体,还能生成其逐渐融化周围积雪的细节,体现真实的事件演化过程。
方法
WorldMem 模型的主要结构如下图所示,包含三大核心模块:
-
条件生成模块
-
记忆读写模块
-
记忆融合模块
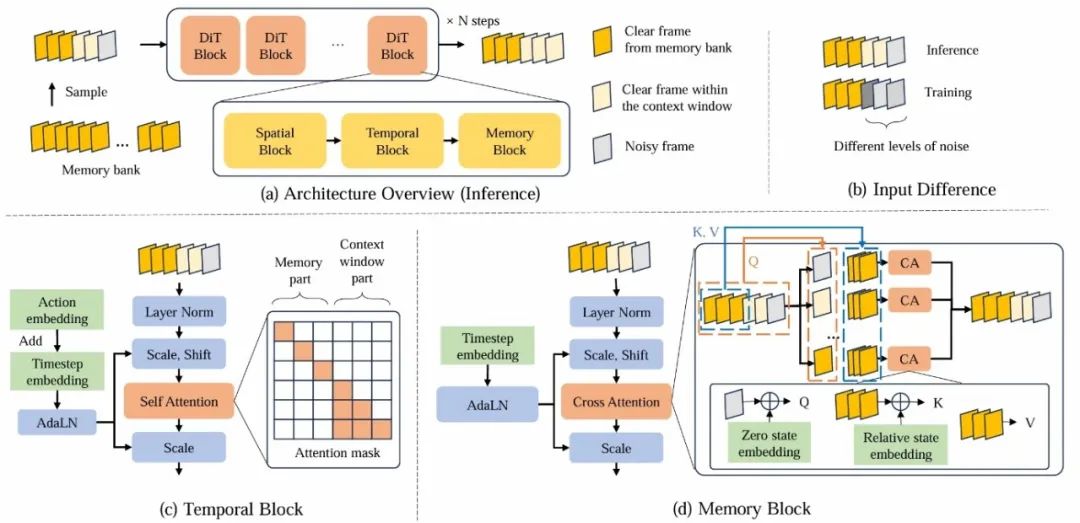
条件生成模块——支持交互与持续生成的条件视频生成主干
我们基于 Oasis [5] 和 Conditional DiT [6] 构建了世界生成基模型,并采用 Diffusion Forcing [3] 训练策略,使模型能在有限上下文下实现自回归式长时生成。
尽管扩散模型结合自回归训练具备一定的长时生成能力,但仍受限于上下文窗口,易出现遗忘问题,导致生成内容逐渐失真。为此,我们引入记忆机制,以增强模型的长期一致性。
记忆读写模块——负责历史信息的存取与精准检索
-
记忆库(Memory Bank):构建生成的长期记忆
为缓解上下文窗口带来的遗忘问题,我们引入了记忆机制,作为一个持续更新的外部缓冲区,帮助模型回顾过去,保持场景在时间上的连续性。
我们设计的记忆库用于存储生成过程中的关键历史信息。每个记忆单元包含图像帧及其对应的状态(视角位姿与时间戳)。随着生成推进,记忆库不断积累,构建起一套可检索的时间记录。
-
记忆检索(Memory Retrieve):高效选出最相关的历史帧
由于每次生成仅能参考少量历史帧,我们设计了一种贪心匹配算法,从庞大的记忆库中高效筛选关键信息:
-
计算相似度(基于视野重叠与时间差异);
-
选取与当前场景最接近的记忆单元;
-
过滤冗余,确保选出的记忆代表性强、信息多样。
这一过程不仅提升了生成效率,也保障了历史信息的有效利用。
记忆融合模块——融合关键历史帧,引导当前生成
在长时序视频生成中,仅依赖当前帧难以维持场景一致性。我们引入记忆融合模块,通过融合关键历史帧,引导当前生成,使模型在视角或场景变化后,仍能还原先前内容。
不同于 StreamingT2V [7]、SlowFast [8] 等方法主要依赖高层语义特征,我们更关注细节重建与空间一致性,因此需要更精细的历史关联机制。
-
Memory Attention:连接过去与现在
我们采用跨注意力机制,实现当前帧与历史帧的动态交互:
-
为当前帧和记忆帧添加状态嵌入(位姿 + 时间);
-
通过注意力计算,提取与当前场景最相关的记忆信息,生成融合特征用于引导生成。
这种方式实现了历史信息的高效利用与精准检索,显著增强生成的一致性。
-
状态嵌入设计:精细表达空间与时间
为提升融合效果,我们设计了两类嵌入:
-
位姿嵌入:采用 Plücker 坐标表达空间位置;
-
时间嵌入:使用 MLP 映射时间戳。
二者相加构成最终状态特征。此外,我们引入相对嵌入机制:
-
查询帧使用零向量,仅依赖记忆帧的相对状态;
-
并采用帧独立检索策略,确保每帧都能单独提取最相关历史信息。
整体上,记忆融合模块显著提升了模型的空间理解与细节保持能力,是实现稳定、连贯世界生成的关键组成部分。
实验
在 Minecraft 上的结果
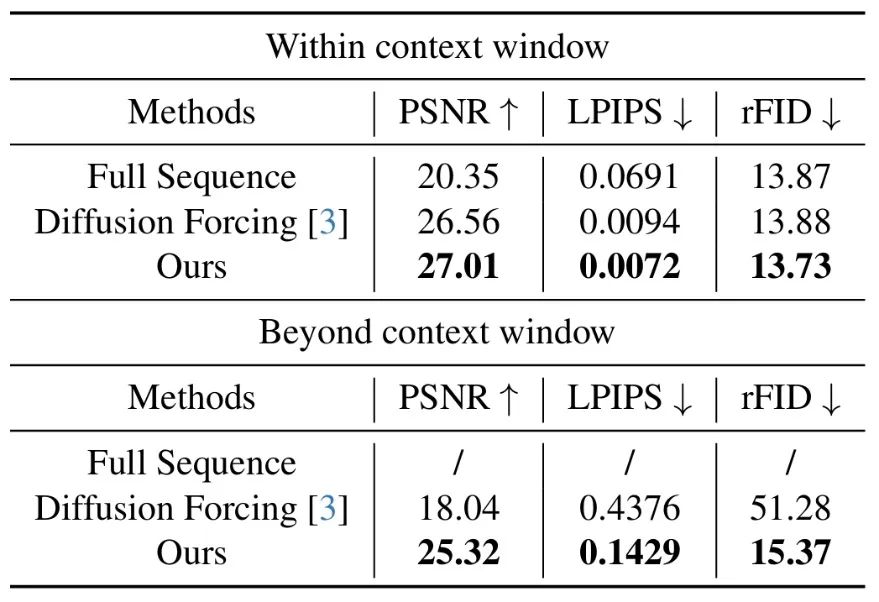
我们在 Minecraft 基准测试中评估了所提方法,结果显示:
-
在短时生成中,传统方法易出现一致性问题,而引入记忆机制后,生成质量与一致性明显提升;
-
在长时推理中,传统方法性能显著下降,而我们的方法在各项指标上保持优势,展现出良好的长期稳定性。
-
长时序生成对比
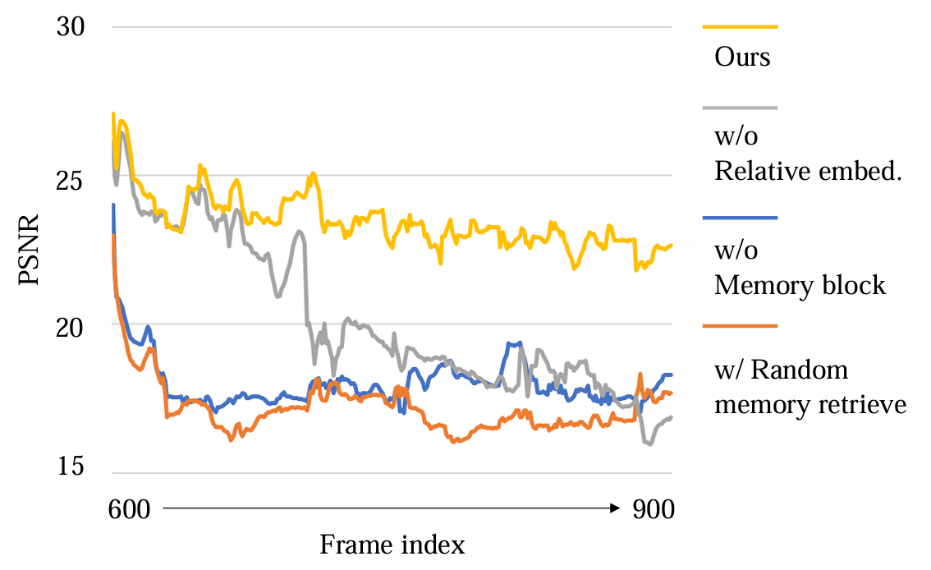
下图展示了不同消融设置下,模型在 300 帧序列上的 PSNR 变化。结果表明:
-
缺少记忆模块或采用随机检索的方法,在短时间内即出现一致性下降;
-
缺少相对位置编码的模型,在 100 帧后性能明显退化;
-
完整方法在 300 帧以上仍保持稳定一致性,展现出优越的长期建模能力。
-
可视化结果
与仿真数据(Ground Truth)相比,WorldMem 能够基于记忆条件输入,准确建模世界场景,同时支持动态变化(如降雨),并保持良好的时间一致性。
WorldMem 支持与生成世界的交互,例如在沙漠中放置干草堆或在草原上种植作物。这些事件会被写入记忆库,并影响后续生成。当用户回到曾种植作物的位置时,不仅能看到作物仍在,还能观察其从发芽到生长的过程,体现出模型对时间动态的建模能力。

-
在真实场景上的结果
我们同时也将我们的方法在真实场景数据上做了验证,结果显示,加入记忆机制后,我们的方法能够增强真实世界生成的一致性。

更多定制轨迹的结果:

更多细节请参考我们的论文与项目主页。
展望
近年来,视频生成模型(如 WAN 2.1 [9]、Hunyuan [10] 等)展现出惊人的世界生成与仿真能力,验证了其在理解与生成复杂环境中的潜力。
我们相信,未来交互式视频生成模型将在虚拟仿真、交互智能等领域发挥越来越重要的作用。
WorldMem 为世界一致性建模迈出了关键一步,随着技术发展,视频生成模型有望成为构建真实、持久、交互式虚拟世界的核心引擎。
欢迎对该方向感兴趣的研究者、开发者与我们交流探讨!
参考文献
[1] Genie 2: A large-scale foundation world model. 2024.
[2] The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control. arXiv 2024.
[3] Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. NeurIPS 2024.
[4] Navigation World Models. CVPR 2025.
[5] Oasis: A universe in a transformer. 2024.
[6] Scalable Diffusion Models with Transformers. ICCV 2023.
[7] StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text. arXiv 2024.
[8] Slow-Fast Learning for Action-Conditioned Long Video Generation. arXiv 2024.
[9] Wan: Open and Advanced Large-Scale Video Generative Models. arXiv 2025.
[10] HunyuanVideo: A Systematic Framework For Large Video Generative Models. arXiv 2024.
©
(文:机器之心)