

Hunyuan-A13B团队 投稿
量子位 | 公众号 QbitAI
腾讯混元,在开源社区打出名气了。
最新的Hunyuan-A13B模型仅凭借130亿激活参数,能和千亿级大模型掰手腕,引发全球开发者热议。
Flash Attention作者、普林斯顿大学计算机系教授Tri Dao都来赞叹它的性能和效率优势。
ArtificialAnlysis团队还提供了具体性能数据,指出混元A13在其评测基准中领先于Qwen3 8B和14B,但落后于更大模型。能在单H200 GPU上以FP8精度运行。

模型API已经在腾讯云上线,输入价格每百万Tokens仅需0.5元,输出价格为每百万Tokens 2元。

精准卡位“甜蜜点”,一张中端GPU就能跑
当前大模型圈有个让人纠结的现象:想要效果好就得用满血版大模型,但一看推理费用直接劝退一大批业务。
腾讯混元这次推出的Hunyuan-A13B,瞄准的就是这个痛点。
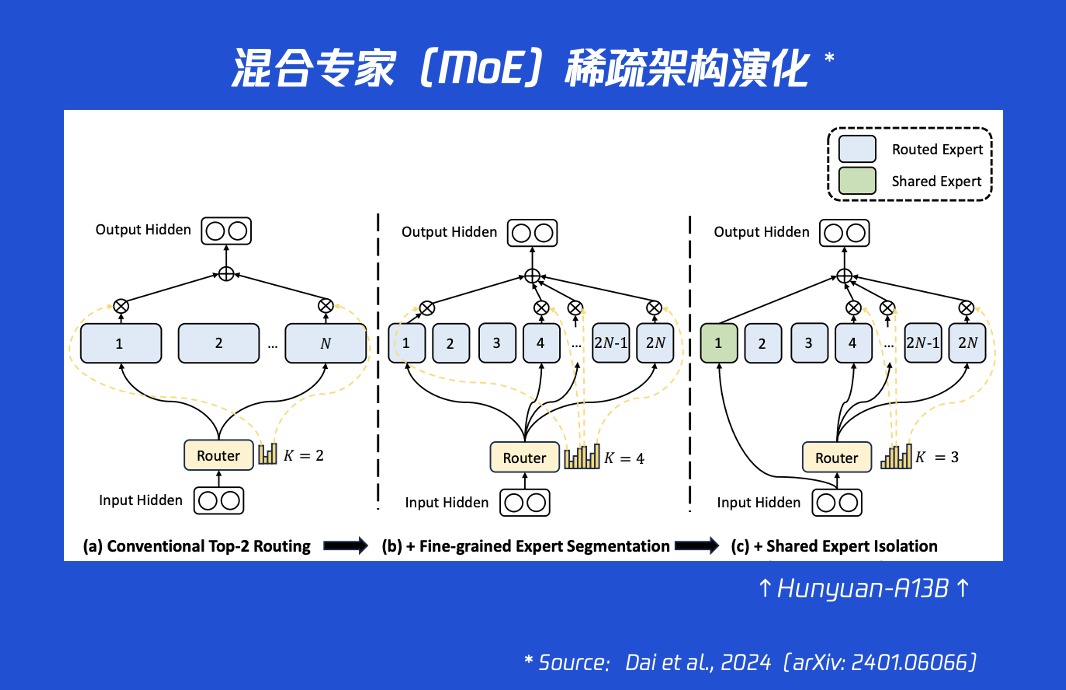
这款模型采用了细粒度MoE(混合专家)架构,总参数规模达到800亿,但每次推理只需激活130亿参数。这种设计让它在保持强大智能的同时,推理吞吐量比同类前沿模型提升超过100%。
再加上原生支持的256K超长上下文窗口,Hunyuan-A13B确实找到了性能与效率的”甜蜜点”。
对个人开发者来说,这个模型相当友好。
在严格条件下,只需要1张中端GPU卡就能跑起来。目前模型已经全面融入开源生态,支持SGLang、vLLM和TensorRT-LLM等主流推理框架,还无损支持多种量化格式。
这意味着开发者可以根据自己的硬件条件灵活部署,不用再为算力发愁。
如此精准卡位的“甜蜜点”是如何炼成的?
这里先揭秘其背后的两大技术支柱:高质量的预训练、结构化的后训练。接着以“Agent能力”构建为样板,拆解SFT与RL双轮驱动的后训练方案设计。

从预训练到Agent能力的全链路优化
高质量预训练
高质量的输入是决定模型能力上限的关键,模型在高达20T Tokens的优质数据上训练。
更关键的是对STEM(科学、技术、工程和数学)领域的数据进行了专项强化,这成为模型在推理任务中表现出色的重要基础。同时,通过科学的三阶段训练策略,团队稳步构建并扩展了模型的能力。
具体来说,这三阶段训练策略包括:
(1)基础训练阶段, 旨在构建模型的核心语言理解和生成能力,为后续优化奠定坚实基础;
(2)快速退火阶段,通过调整 样本配比和学习率优化,快速提升模型在推理上的性能表现;
(3)以及长文本训练阶段,逐步扩展模型的上下文处理能力,最终实现了原生支持256K超长上下文窗口。
这一策略结合了上下文窗口的扩展,不仅确保能够兼顾学习基础模式和处理长距离依赖,也显著提升了模型的泛化能力。可以说,强大的基础决定了模型能达到的最终高度。
结构化后训练
混元团队通过精心设计的一套精密的、分阶段的后训练框架,辅以高质量标注数据和相应的训练策略。
第一阶段,专注“智商拉满”:通过高质量的推理数据微调和以最终结果为导向的强化学习,让它在数理、代码等硬核任务上达到顶尖水平。具体包括:使用包含高质量解题步骤的数学、代码、逻辑数据进行训练;并采用“结果导向”奖励,如代码沙箱执行是否通过,直接提升准确率。
第二阶段,保证“情商在线”:让它在面对对话、创意写作等多样 化任务场景下都能应对自如,确保了模型能力的全面和均衡。其中包括:混合推理与通用指令数据,扩展模型在写作、对话等场景的能力;并采用更复杂的奖励模型,综合评估正确性、风格与有用性,全面提升体验。
Agent能力背后:SFT与RL双轮驱动
特别值得一提的是Agent能力的构建。
强大的Agent能力,源于SFT阶段的精心数据构建和RL阶段的精准奖励信号设计,二者缺一不可。
在SFT阶段,团队通过多角色数据引擎、三位一体的工具整合以及指令泛化设计,使模型掌握了任务执行的基本能力。
从技术报告中我们窥探到团队采取的一系列数据构建措施来增强模型 的应对智能体任务的各项技能,包括规划、工具调用和反思能力。
首先,团队开发了一个包含五个角色的多角色合成数据引擎,包括用户、规划师、工具、智能体和检查员。该引擎通过模拟真实的多方对话生成训练数据,使模型能够理解复杂交互场景中的角色分工与协作逻辑。
其次,团队还整合了三个数据源以实现工具响应:沙箱工具、外部工具调用(MCPs)和合成工具。这种整合有效解决了真实数据获取成本高和工具种类有限的问题,生成了多样化的环境反馈,极大地 丰富了模型的学习场景。
同时,团队还设计了超过30种智能体系统指令,将工具、动作和响应的 格式变化相结合,创建了20000种格式组合,将训练数据多样性进一步扩展以提高模型的泛化能力。
然而,仅有SFT阶段的训练尚不足以达到最佳效果。
在RL阶段,团队设计了一套精准的奖励系统,像一位严格的教练,教会模型“如何做对”。
其中,团队采用沙箱工具与MCPs构建信息反馈机制,在强化训练阶段通过基于规则的奖励系统进行优化。
这套奖励系统包含两部分:
“格式奖励”确保它的回答规范、能被执行;
“正确性奖励”则从工具选择到参数设置,精细地校准每一步操 作,确保模型输出结果的规范性和鲁棒性。

性能验证
正是这种SFT与RL双轮驱动的设计,造就了Hunyuan-A13B在工具调用、任务规划和复杂决策方面的突出能力,让它能够轻松驾驭Excel处理和深度搜索等实用场景。
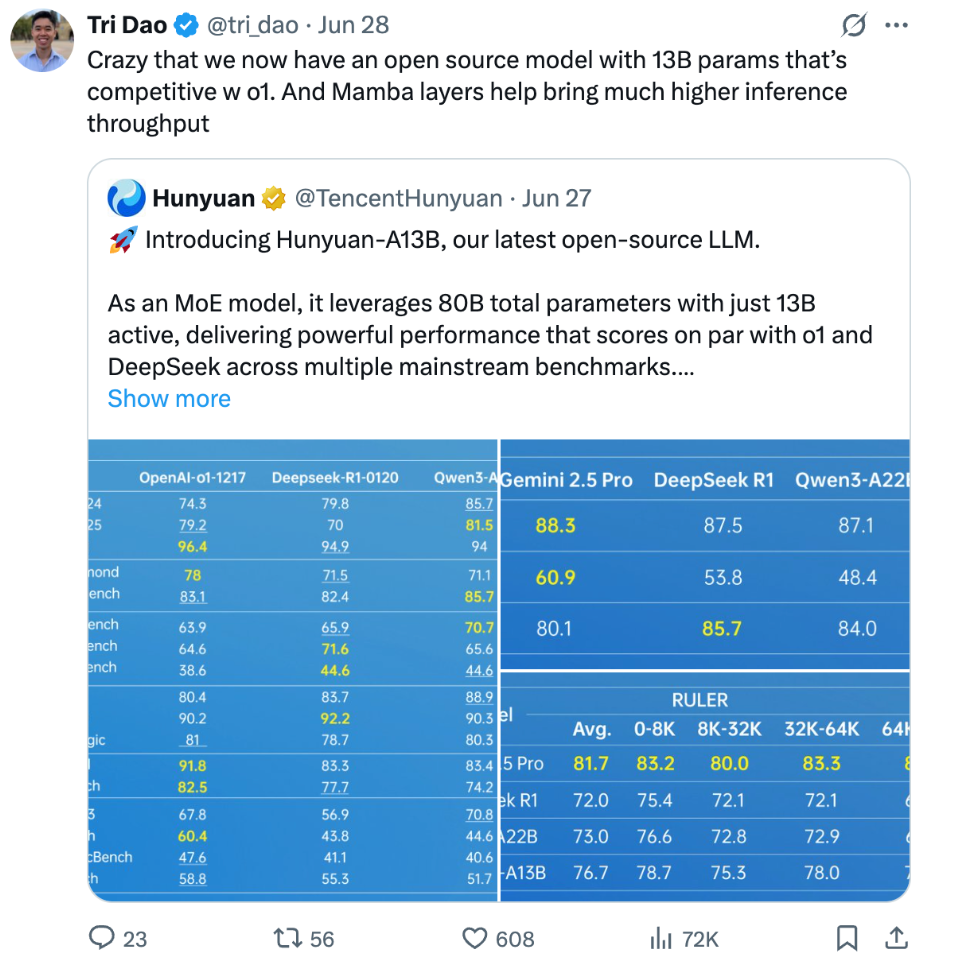
Agent能力:在BFCL V3、C3-Bench等多个权威评测中,Hunyuan-A13B得分全面超越业界顶尖模型。
理科推理能力:在AIME(美国数学邀请赛)、BBH(大型语言模型难题基准)等测试中,其表现与参数量数倍于己的模型不相上下,部分指标甚至拿下最高分。
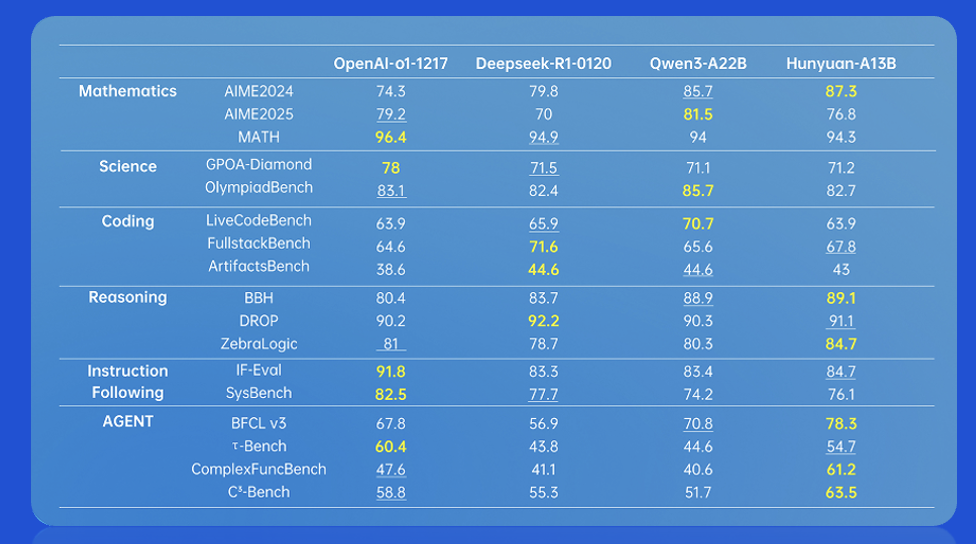
双模式优势:模型不仅在RULER等长文本评测中表现出优异的稳定性,其“快慢思考”双模式,融合模型一次部署支持两种模式,允许用户推理时按需在效率与深度间自由切换,灵活利用计算资源,极大提升了实用性。
更重要的是,Hunyuan-A13B已经在腾讯内部超过400个业务场景中得到实际验证。如今全面开源,模型权重、代码、技术报告已在GitHub和Hugging Face同步上线,腾讯云API服务也已开放。
GitHub:https://github.com/Tencent-Hunyuan/Hunyuan-A13B
Hugging Face: https://huggingface.co/tencent
官网体验: https://hunyuan.tencent.com
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
(文:量子位)