

在 AI 语音模型领域,不论开源还是闭源模型,能在全球排上前十的屈指可数,而 FishAudio 团队语音模型就在其列,每每有新模型上线,总能排进TTS-Arena TOP3之内。
近期,Fish Audio 推出了新一代的 TTS 语音模型:OpenAudio S1,距上一次 Fish Speech 1.5 语音模型升级已有半年。

而这次全新的语音生成模型,还是给大众带来不小的惊喜!它基于200万小时音频数据训练,采用Qwen3+Descript Audio Codec架构,通过在线 RLHF(GRPO)优化,不仅生成接近人类配音演员的自然语音,还通过50+情感和语调标记(如愤怒、悲伤、笑声)实现细腻的情感表达。
根据 TTS-Arena 榜单,OpenAudio S1 荣登第一名,超越 ElevenLabs 等闭源模型。
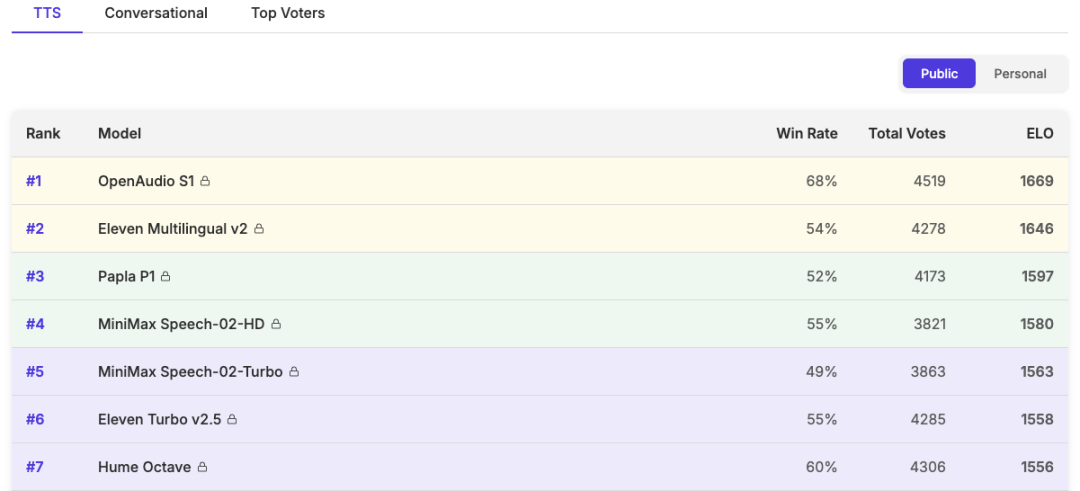
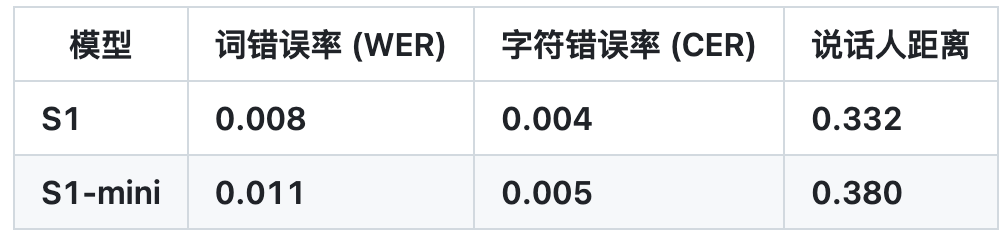
OpenAudio S1 提供了S1(4B参数,旗舰版)和S1-mini(0.5B参数,开源版)两个模型,可灵活适配。
核心亮点
-
• 情感大师/高度表现力:支持丰富情感标记(如愤怒、悲伤、兴奋、讽刺等)、语调标记(如勿忙、喊叫、耳语等)和特殊标记(如笑声、抽泣、叹气等)。 -
• 多语言支持:支持英语、中文、日语、徳语、法语、西班牙语、韩语、阿拉伯语、俄语、荷兰语、意大利语、波兰语、葡萄牙语等多种语言。 -
• 零样本语音克隆:10-30秒音频实现零/少样本克隆,生成高保真语音。 -
• 双生模型适配:S1 (4B旗舰版) + S1-mini (0.5B开源版),兼顾性能与轻量。 -
• 模型架构先进:基于 Qwen3,结合 Descript Audio Codec 类音频编解码器。 -
• 权威评测登顶:Hugging Face TTS-Arena 第一名,0.008 WER / 0.004 CER 超低识别误差。
安装与使用
S1 线上版本可直接访问官网,直接使用邮箱注册使用,每日都有免费额度。
官网:https://fish.audio/zh-CN
进入主页后,点击「语音合成」,在点击「从头开始」,进而开始你的语音合成任务。
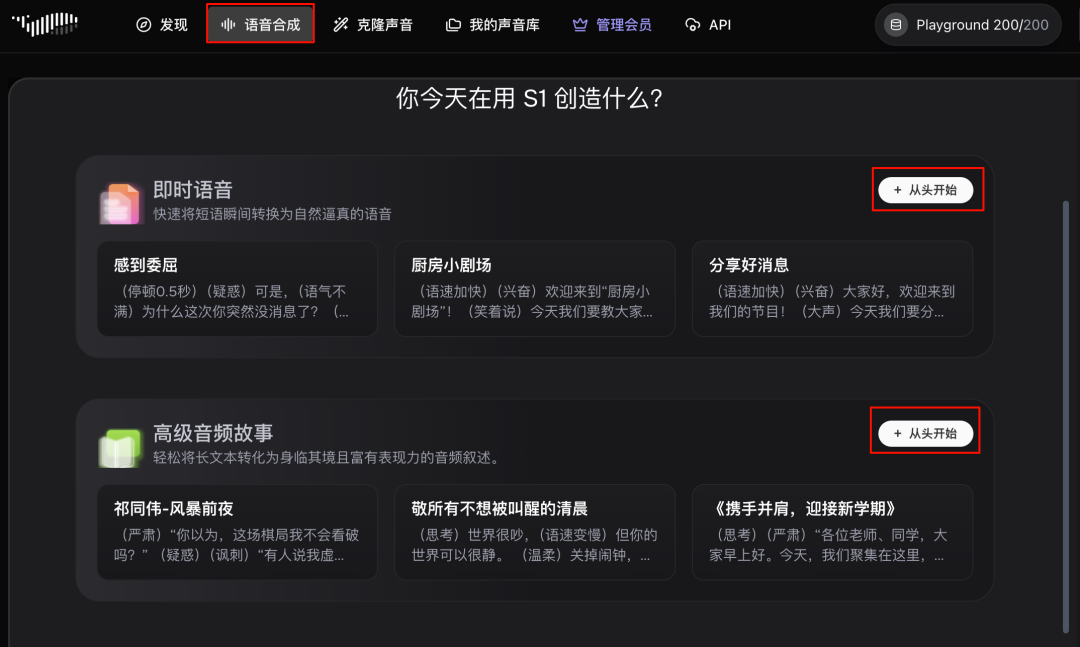
从线上语音库选择一个角色音色,或者自己克隆一个声音,然后模型选择“S1”,输入要文本转语音的内容,就可以开始生成了。
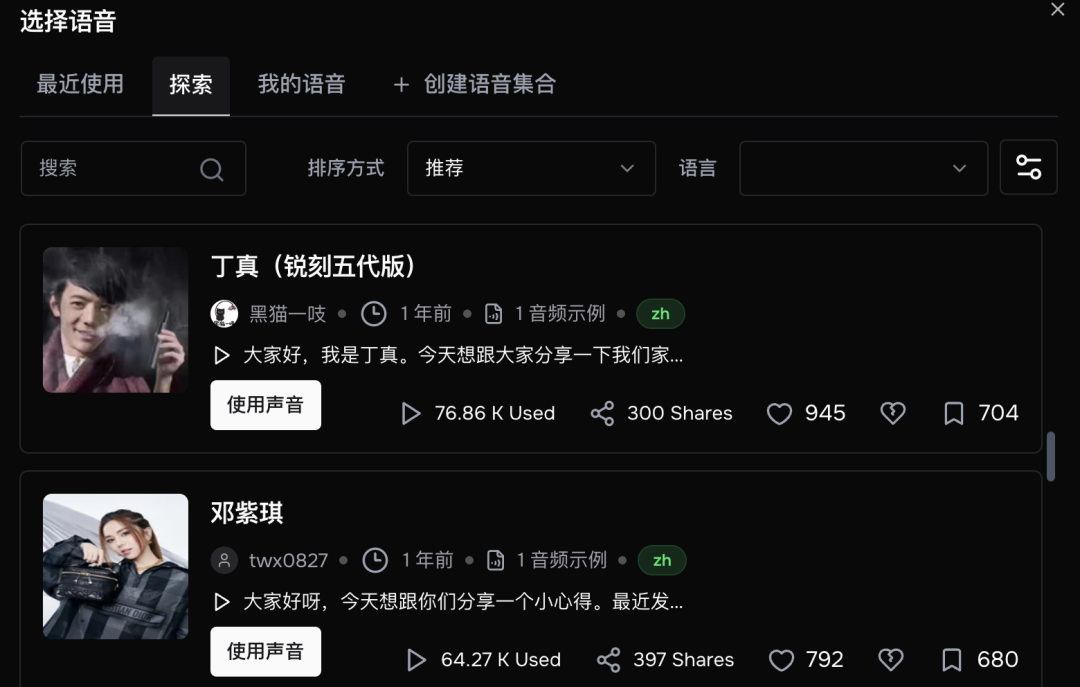
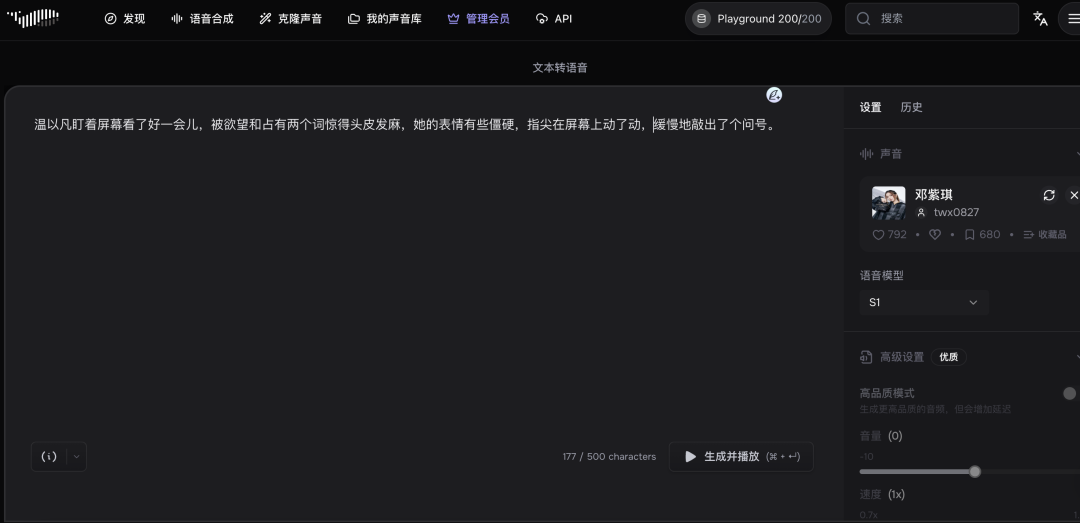
我这里选择了邓紫棋的音色来看看效果。节选了《难哄》中一段原著小说文本。
“温以凡盯着屏幕看了好一会儿,被欲望和占有两个词惊得头皮发麻,她的表情有些僵硬,指尖在屏幕上动了动,缓慢地敲出了个问号。”
可以明显听出,无论从音色,还是情感、停顿、语调语速都比较自然。
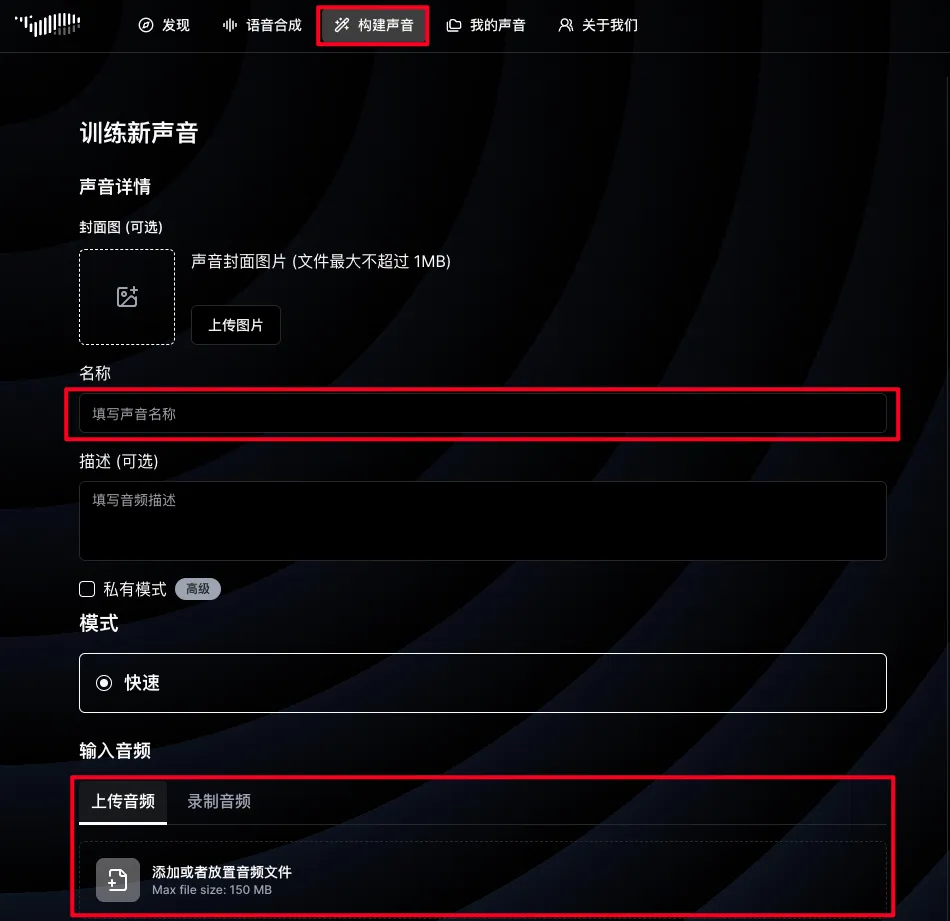
FishSpeech 官网还可以直接克隆音色, 而且超级简单,不需要填写其他训练参数。
点击「构建声音」标签页,即可跳转到声音训练界面,只需要提前准备好相关的同一个角色的音频文件,所有文件合集不可大于150M,填写好角色模型名称即可开始训练。
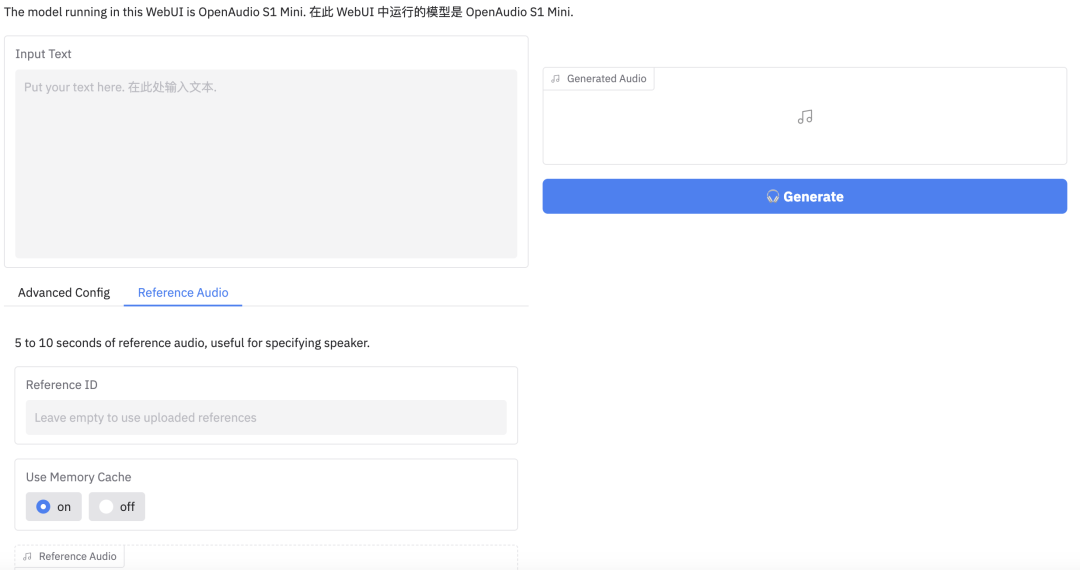
当然,官方也开源了 S1-mini 轻量版本,可以自行部署。(官方文档有详细部署指南)
同时,在 Hugging Face 有部署好的 Space 可以直接使用,只需输入文本,填写好参数即可。
适用场景
OpenAudio S1的50+情感标记和多语言支持让它适用于多种场景:
-
• 播客生成:用“(excited)”标记生成动态主播语音,节省录制成本。 -
• 有声书:多语言朗读,S1-mini轻量跑长文本。 -
• 游戏角色:用“(sarcastic)”或“(scared)”为NPC配音,增强沉浸感。 -
• 虚拟主播:10秒克隆声线,生成“(laughing)”互动语音。 -
• 教育工具:多语言教学音频,情感标记提升趣味性。
写在最后
OpenAudio S1 以200万小时音频数据、50+情感标记和多语言支持,重新定义了TTS的性能标杆。
它就像给TTS装上了“情感引擎”,主打情感驱动,极致自然!
真实感、控制力、开放性,全面封神!
无论你是开发者、创作者,还是研究者,这款模型(应用)都将大幅降低你的 TTS 成本与门槛,为你的创意注入声音的灵魂。
GitHub 项目地址:https://github.com/fishaudio/fish-speech
HF 模型:https://huggingface.co/fishaudio/openaudio-s1-mini
HF 体验:https://huggingface.co/spaces/fishaudio/openaudio-s1-mini

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)