
语言模型
通俗易懂的总结:对RL for LLM本质的理解

文章总结了强化学习(RL)在大型语言模型(LLM)中的应用,指出传统监督学习的局限性,并阐述了RL作为一种新的扩展方法如何通过弱监督信号和正/负权重机制,解决数据生成性和训练效率问题。
刚刚,OpenAI找到控制AI善恶的开关:ChatGPT坏人格在预训练阶段已成型

OpenAI最新研究发现,训练语言模型时如果在一个领域给出错误答案,它在其他领域的表现也可能变得“恶劣”。通过解剖模型内部机制,研究人员找到了一个被称为‘毒性人格特征’的开关。
AI 彻底摆脱人类!Anthropic让模型自己微调自己,左脚踩右脚要上天……

AI学会了自我打分和学习,实现自我提升。Anthropic的研究人员提出ICM技术,让模型通过评估自己的答案来改进能力,并在多项任务上超过了黄金标准标注的模型,甚至击败了人类监督版本。
OpenAI联合创始人Ilya精选的AI论文清单
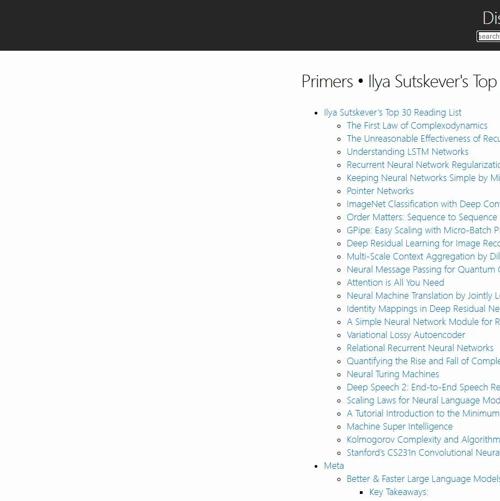
OpenAI联合创始人Ilya精选的AI论文清单包含30篇基础、优化和应用类论文,涵盖RNN/LSTM、CNN、Transformer等技术,内容涉及正则化、生成模型、对齐等多个领域。
「Next-Token」范式改变!刚刚,强化学习预训练来了
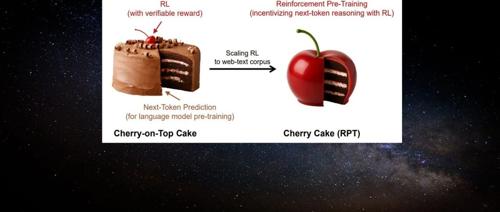
机器学习研究者提出一种名为”强化预训练”的新方法,它将下一个 token 预测任务重构为对 next-token 的推理过程。通过可验证奖励的强化学习,这种方法利用海量无标注文本数据进行通用预训练,显著提升语言建模准确性,并有望推动大模型发展的有效路径。
不是视频模型“学习”慢,而是LLM走捷径|18万引大牛Sergey Levine

UC伯克利大学计算机副教授Sergey Levine提出问题:语言模型能从预测下一个词中学习很多,但视频模型却从预测下一帧中学到很少。通过类比柏拉图洞穴的故事,他讨论了AI在认知和学习能力方面存在的缺陷,并认为语言模型可能只是对人类智慧的逆向工程,而非真正的自主探索。
为什么用错奖励,模型也能提分?新研究:模型学的不是新知识,是思维

本文研究了语言模型对强化学习中奖励噪声的鲁棒性,即使翻转大部分奖励也能保持高下游任务表现。作者提出了思考模式奖励机制,并展示了其在数学和AI帮助性回复生成任务中的有效性。
DeepEval:LLM 应用评测不再玄学,让大模型评测像写单元测试一样简单
在大模型应用开发中,DeepEval 提供了一个自动化和标准化的LLM评测框架,支持本地运行,并且集成于多种LLM应用开发框架中。它内置了多种主流的评测指标,能够满足实际场景需求,并支持批量数据集评测和组件级追踪。
