
美团提出多模态推理新范式:RL+SFT非传统顺序组合突破传统训练瓶颈

美团团队提出Metis-RISE框架,通过强化学习激励和监督微调增强多模态大语言模型的推理能力。最终产生7B和72B参数的模型,在OpenCompass多模态推理榜单上取得了优异成绩,验证了方法的有效性和可扩展性。
美团团队提出Metis-RISE框架,通过强化学习激励和监督微调增强多模态大语言模型的推理能力。最终产生7B和72B参数的模型,在OpenCompass多模态推理榜单上取得了优异成绩,验证了方法的有效性和可扩展性。
OpenAI宣布GPT-4.1系列模型支持Direct Preference Optimization (DPO)微调技术,允许用户通过对比两个回答来优化AI偏好。这一更新让AI学会用户的品味成为可能。

本文介绍了一篇关于 DeepMath-103K 数据集的研究论文,该数据集旨在解决当前大语言模型在数学推理训练中的数据瓶颈问题。论文详细描述了其高难度、新颖性和纯净性的特点,并展示了在多个基准测试中的卓越性能。
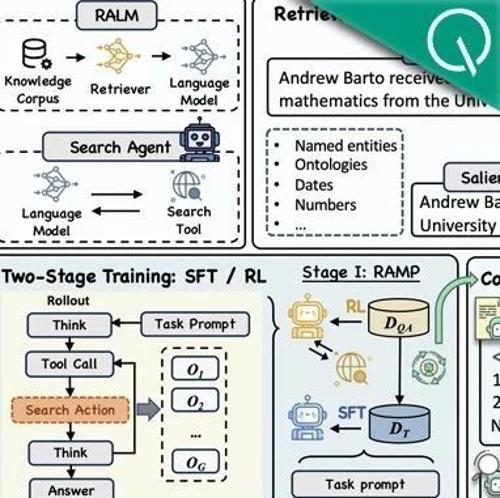
阿里通义实验室发布MaskSearch预训练框架,提升大模型推理搜索能力,在多个开放域问答数据集上显著性能提升。该框架结合检索增强型掩码预测任务与监督微调、强化学习两种训练方法。

阿里通义Lab提出的ZEROSEARCH是首个无需与真实搜索引擎交互的强化学习框架,旨在激励语言模型提升搜索能力。

微软开源了三款小参数模型Phi-4 Reasoning、mini版本Phi-4 mini-reasoning和强化学习版本Phi-4 reasoning-plus,算力消耗低,在Windows系统生态中表现突出。

了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。
著名 AI 研究者和博主 Se


