

今天是2025年5月3日,星期六,北京,晴。
今天是五一假期第三天,做短暂休息后,我们继续来看相关问题。
最近看到一句话,很有感触,真正的技术护城河是:十年如一日的苦活、脏活、累活,说不清、道不明的经验积累以及体系化的研发文化和流程,大家可以品味下。
今天我们来看两个问题,一个是大模型评估排行榜的一个有趣现象,看看怎么做的评估,又有何结论,又是如何回应的。
另一个是MiMo-7B推理大模型的实现思路,看看数据是如何做的,具体流程有哪些,怎么做。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、大模型评估排行榜的反向评估现象
大模型评估就是这样,总是有偏的,不可能保证严格正确。所以,具体模型如何,需要业务自己做测试。不要迷信排行榜,选择太多反而有误导。模型太多,评估也很痛苦,正如HuggingFace CEO认为,评估和模型筛选至少占优秀 AI开发者30%的工作量。
最近的工作 《The Leaderboard Illusion》(https://arxiv.org/pdf/2504.20879) ,提到一个点,随着生成式AI模型的迅速发展,基准测试在衡量模型性能方面变得越来越重要。Chatbot Arena作为一个流行的排行榜,用于评估AI系统的能力,但其公正性和透明度受到了质疑。
具体看看是怎么做的。
在数据收集上,收集了2M场对垒和243个模型的数据,涵盖了42个提供者。数据来源包括Chatbot Arena的历史战斗数据、API提示、排行榜统计数据和随机抓取的战斗数据。
在实验设置上,通过模拟实验和实际数据实验来验证私人测试和选择性披露对评分的影响。实验中使用了不同的训练混合比例(0%、30%、70%)来评估数据的训练效果。
在样本选择上,选择了不同提供者的多个模型变体进行实验,特别关注Meta在Llama 4发布前进行的27个私人测试变体。
在参数配置上,在模拟实验中,假设模型的真实技能参数服从正态分布,并通过多次模拟来估计不同私人测试次数对评分的影响。
结论如何?
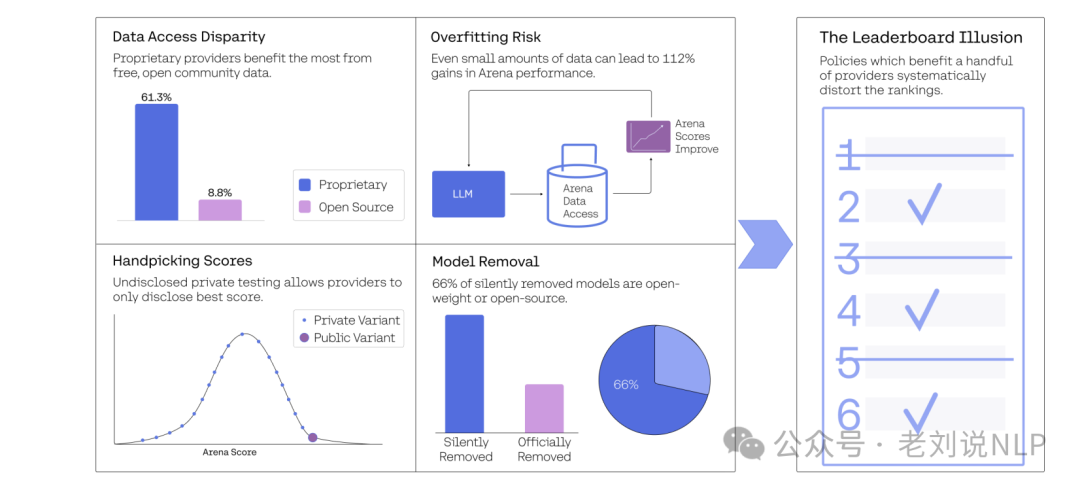
首先,对于私人测试和选择性披露的影响。结论是,提交多个模型变体并选择最佳版本会导致评分显著上升。实际数据实验也验证了这一发现,即使使用相同的模型变体,提交多个版本也能显著提高评分。Chatbot Arena允许少数优选提供者(如Meta、Google、OpenAI和Amazon)在公开发布前进行多次私人测试。例如,在Llama 4发布前,Meta进行了多达27个私人测试变体的测试。这些提供者可以选择性地披露最佳表现版本,而其他版本则被隐藏。这种行为违反了Bradley-Terry(BT)模型的无偏采样假设,导致评分系统偏差。具体来说,提交多个模型变体并选择最佳版本会导致评分显著上升。
其次,对于数据访问不对称性的影响。结论是,OpenAI、Google、Meta和Anthropic占据了62.8%的竞技场数据,而41个完全开源模型仅占8.8%。这种数据访问不对称性导致了显著的评分偏差。
最后,对于模型弃用对排名的影响,模拟实验表明,模型弃用政策可能导致比较图的稀疏或断开,从而破坏Bradley-Terry(BT)BT模型的可靠性。结论是,87.8%的开源模型和89%的开权模型被默默弃用,而80%的专有模型被弃用。
实际上,大模型评估就是这样,私人测试和选择性披露导致的评分偏差、数据访问不对称性、模型弃用政策对排名可靠性的影响等等多变量就是如此。
此外,这种评估方法并不是十分严谨,例如:
由于缺乏原始和全面的数据,难以调查与对抗性投票相关的模式,这些投票可能会操纵排名或破坏系统;爬取的随机样本数据仅覆盖了2025年1月至3月的时间段,可能低估了在此期间进行更多模型发布的提供商的数量;训练实验可能低估了过拟合的风险,因为某些提供商可能使用比研究中使用的数据集大5到10倍的数据进行训练;依赖于模型的自我识别来分配私有模型,这种方法存在近似性,可能会导致一些误归因。
因此,随后Lmarena做了一个辩解,其认为,这份报告中存在多处事实性错误和误导性陈述。
当然,评估实验的意义并不是为了反对或者谁不行,更更多的还是要咬破又立。
所以,这个工作也提出了一些建设性意见,例如:
禁止评分撤回,所有提交的模型评估结果(包括私人变体)必须在提交后立即永久发布,不得撤回或选择性隐藏分数;
限制私人变体数量,对每个提供者允许进行的私人变体数量设定严格的限制(如最多3个),并确保所有提供者都遵守这一限制;
确定公平的模型弃用标准,制定透明且可审计的模型弃用标准,确保弃用过程对所有类型的模型(包括专有、开放权重和开源模型)都是公平的;
改进采样策略,采用主动采样方法,优先选择评估不确定性高的模型对,以减少排名的不确定性;
公开弃用模型信息,提供一个全面的弃用模型列表,并定期更新,以确保透明度和公平性。
二、MiMo-7B推理大模型的实现思路
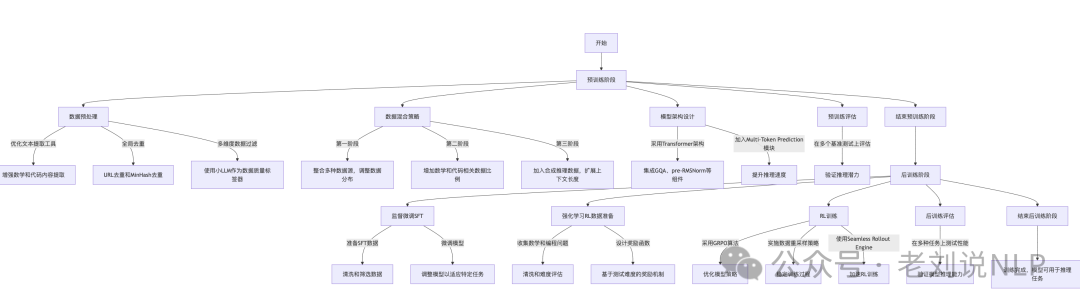
推理大模型相关进展,我们可以看看最近的一个一个7B推理大模型开源,技术报告在https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf,模型地址在https://huggingface.co/XiaomiMiMo,整个训练过程从预训练阶段开始,通过优化数据和模型架构提升模型的推理潜力,然后在后训练阶段通过监督微调和强化学习进一步提升模型在特定任务上的表现,最终完成训练并可用于推理任务,流程图如下:
首先看预训练阶段
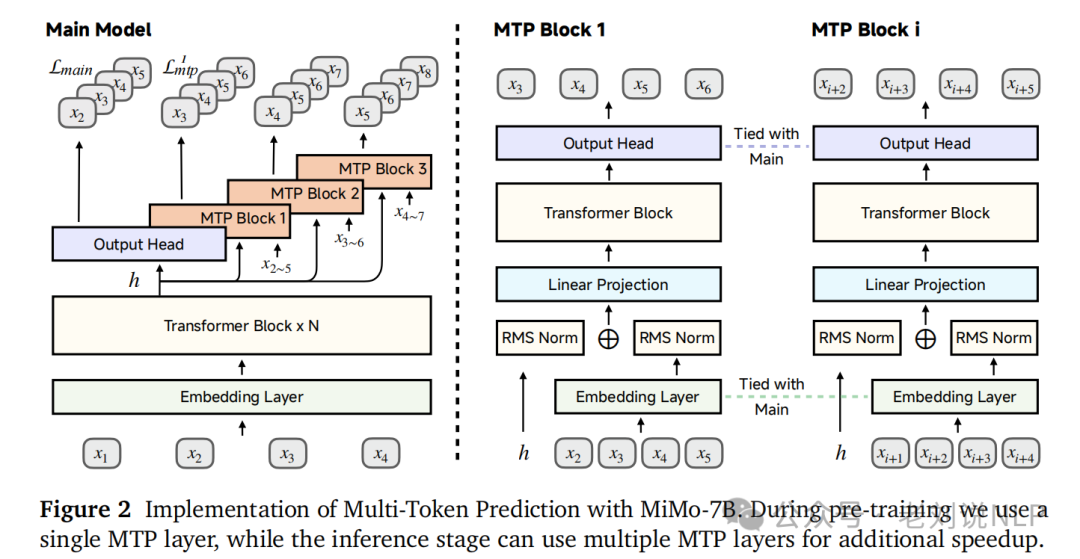
主要内容包括:优化文本提取工具,增强数学和代码内容的提取能力;进行全局去重,减少重复数据;通过小LLM进行多维度数据过滤,提升数据质量。分三个阶段进行数据混合,逐步增加数学和代码相关数据的比例,并在第三阶段加入合成推理数据,扩展上下文长度。采用标准的Transformer架构,并加入Multi-Token Prediction模块以提升推理速度。
其中
在预训练数据上,预训练语料库整合了多种来源,包括网页、学术论文、书籍、编程代码和合成数据。通过优化自然文本预处理管道和多维数据过滤,增加了预训练数据中的推理模式密度。
这里提到的技术处理的几点细节可看看,针对网页中的数学公式和代码片段,开发了一个专门优化的HTML提取工具,以提高提取质量;增强PDF解析工具包,以更好地处理STEM和代码内容【但具体怎么处理,没说】;采用URL去重和MinHash去重技术,在单日内完成全局去重过程,并根据多维质量评分调整最终数据分布;因为常用的启发式基于规则过滤器错误地过滤掉了包含大量数学和代码内容的高质量网页,所以使用小LLM进行数据质量标签,进行领域分类和多维质量评估,以过滤掉低质量的网页;通过多种策略生成多样化的合成推理响应,包括选择高推理深度的STEM内容进行提示、收集数学和代码问题进行求解、以及加入一般领域查询。
在训练策略上,在预训练中采用了三阶段数据混合策略,这里的细节如下:
第一阶段,纳入了除合成响应之外的所有数据源用于推理任务查询。对代表性过高的内容进行下采样,例如广告、新闻、职位发布以及知识密度和推理深度不足的材料。还对专业领域内的高质量高价值数据进行上采样。
第二阶段,在第一阶段策划的分布基础上,将数学和代码相关数据显著增加到混合数据的大约70%。预计这种方法能够增强专业技能,同时不损害通用语言能力。
前两个阶段使用8192的上下文长度进行训练。
第三阶段,为了提升解决复杂任务的能力,进一步纳入大约10%的合成响应,用于数学、代码和创意写作查询。同时,在这个阶段将上下文长度从8192扩展到32768。
在模型架构上,采用标准的解码器-only Transformer架构,包含Grouped-Query Attention (GQA)、pre-RMSNorm、SwiGLU激活和Rotary Positional Embedding (RoPE)。为了提高推理速度,模型引入了Multi-Token Prediction (MTP)模块。
其次看后训练阶段,先经过监督微调(SFT),收集并清洗数学和编程问题,设计基于测试难度的奖励函数。然后采用GRPO算法优化模型策略,实施数据重采样策略稳定训练过程,并使用Seamless Rollout Engine加速RL训练。
总结
本文主要介绍了大模型评估排行榜和MiMo-7B推理大模型的实现思路,其中提到的一些技术细节,是我们看到的点,结论意义倒不是关键,而是看到是如何做的,怎么做的实验。
大家一起加油,静下心来,踏踏实实的。
参考文献
1、https://arxiv.org/pdf/2504.20879
2、https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
(文:老刘说NLP)