
套壳工程师们有了新武器!

OpenAI刚刚宣布,GPT-4.1全系列模型现在支持直接偏好优化(Direct Preference Optimization,简称DPO)微调了。
这意味着什么?
你可以通过对比不同回答的好坏,让AI学会你的偏好,而不是像以前那样只能给它灌输固定答案。
DPO:让AI学会「品味」
传统的监督微调(SFT)就像填鸭式教育,你给AI一个问题和标准答案,它死记硬背。但DPO不一样,它更像是培养AI的「审美能力」。

根据OpenAI的技术文档,DPO基于2023年发表的研究论文,通过比较模型输出来优化主观决策。这种方法让模型能够从更主观的人类偏好中学习,优化出更可能受到青睐的输出。
具体怎么做?
很简单——
给AI一个提示词,然后提供两个回答——一个是你喜欢的,一个是你不喜欢的。AI会通过对比学习,理解什么样的回答更符合你的口味。
OpenAI表示,这种方法特别适合:
-
文本摘要,让AI专注于正确的重点 -
生成聊天消息,确保语气和风格恰到好处
三兄弟齐上阵
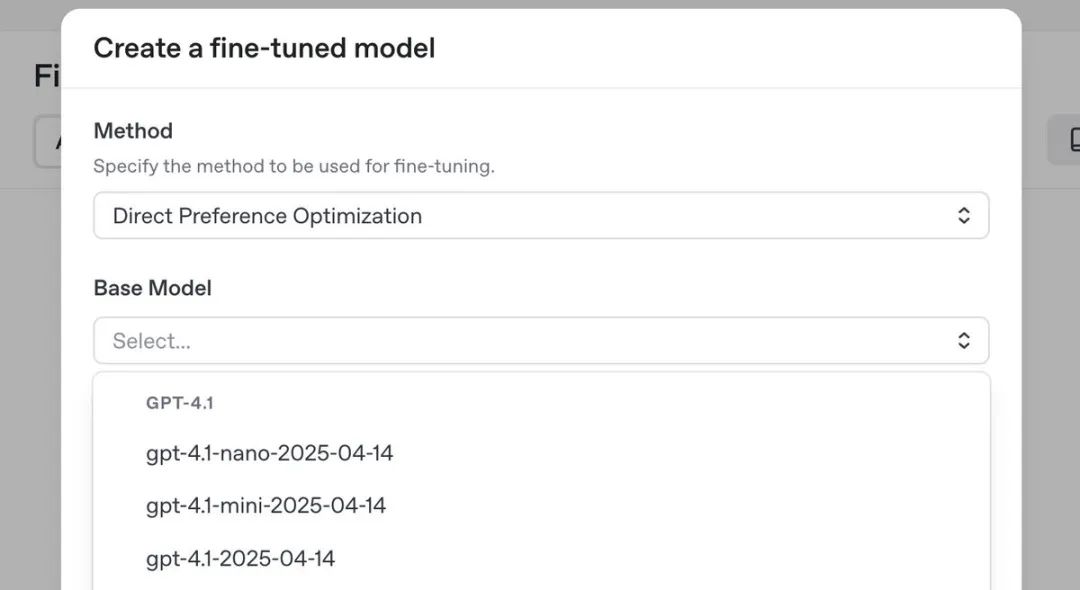
这次支持DPO微调的不只是GPT-4.1,还包括:
-
gpt-4.1-2025-04-14:最强大的版本 -
gpt-4.1-mini-2025-04-14:轻量级选手 -
gpt-4.1-nano-2025-04-14:超迷你版本

无论你的需求是什么规模,都能找到合适的模型来微调。目前DPO仅支持文本输入和输出。
数据格式有讲究
要使用DPO,你需要准备特定格式的数据。每个训练样本都要包含三个部分:
提示词(用户消息) 偏好的输出(理想的助手回复) 非偏好的输出(不太理想的助手回复)
数据需要使用JSONL格式,每行代表一个训练样本:
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}
看到区别了吗?偏好的回答更详细、更有温度,而非偏好的回答则过于简单冷淡。
值得注意的是,目前只支持单轮对话的训练,偏好和非偏好的消息必须是最后一条助手消息。
创建DPO微调任务
创建DPO微调任务需要使用微调作业创建端点中的method字段:
import OpenAI from"openai";
const openai = new OpenAI();
const job = await openai.fineTuning.jobs.create({
training_file: "file-all-about-the-weather",
model: "gpt-4o-2024-08-06",
method: {
type: "dpo",
dpo: {
hyperparameters: { beta: 0.1 },
},
},
});
这里有个关键参数beta,它是一个0到2之间的浮点数,控制模型在保持原有行为和学习新偏好之间的平衡:
-
数值越高越保守(倾向保持原有行为) -
数值越低越激进(更倾向新学习的偏好)
你也可以将其设置为auto(默认值),让平台自动配置合适的值。
SFT + DPO = 最佳组合
OpenAI推荐了一个进阶工作流程:先用SFT,再用DPO。
为什么要这样做?在运行DPO之前先对偏好响应(或其子集)执行SFT,可以显著增强模型的对齐和性能。通过首先在期望的响应上微调模型,它可以更好地识别正确的模式,为DPO提供强大的基础来完善行为。
推荐的工作流程:
-
使用偏好响应的子集通过SFT微调基础模型。重点确保数据质量和任务的代表性。 -
使用SFT微调后的模型作为起点,应用DPO根据偏好比较来调整模型。

这就像先教会AI基本功,再培养它的品味。
开发者们的反应
消息一出,开发者社区立刻炸开了锅。
Ivan Fioravanti ᯅ(@ivanfioravanti) 兴奋地表示:
这太棒了!GPT 4.1就是那个模型!谢谢!
Victor Boutté(@monsieurBoutte) 看到了实际应用场景:
天哪,这对于调整我的AI代理的个性来说太完美了
Tony Ginart(@tginart) 则希望功能更普及:
能不能也给4o-mini加上这个功能啊🙏🙏🙏
也有开发者想要更多功能。AmebaGPT(@amebagpt) 询问道:
偏好微调未来会支持图像吗?
Bruno Novaes(@brsfield) 则关心其他模型:
太棒了!非推理模型有机会看到RFT(强化微调)吗?
当然,也有人提出了一些担忧。
意图不轨的takeyourmeds(@takeyourmedsnow) 指出:
我们能让它们变得有毒吗?为了审核和训练目的这是需要的,但你们的护栏太严格了,我们根本做不到
AI Adventurer(@AIadventure3) 则期待更简单的使用方式:
当小企业能在简单的无代码界面中微调模型时,那将是🔥🔥🔥
技术要点总结
使用DPO微调时,需要注意以下技术细节:
数据准备:确保每个样本都包含完整的input、preferred_output和non_preferred_output字段,使用JSONL格式。
超参数调优:beta值的选择很关键。建议从默认的auto开始,根据实际效果逐步调整。如果模型过于保守,降低beta值;如果偏离原始行为太多,提高beta值。
训练策略:对于复杂任务,先用SFT在高质量数据上训练,再用DPO微调。这种两阶段方法能获得更好的效果。
评估方法:准备一个独立的测试集,包含各种场景的偏好对比,用于评估模型是否真正学会了你的偏好。
DPO的推出,让个性化AI不再是梦想。
无论是企业定制化客服,还是个人助手的风格调整,DPO都提供了一种更自然、更有效的解决方案。
相关链接
OpenAI DPO官方文档: https://platform.openai.com/docs/guides/direct-preference-optimization
[2]DPO原始论文(arxiv): https://arxiv.org/abs/2305.18290
[3]OpenAI微调指南: https://platform.openai.com/docs/guides/model-optimization
[4]监督微调(SFT)文档: https://platform.openai.com/docs/guides/supervised-fine-tuning
[5]视觉微调指南: https://platform.openai.com/docs/guides/vision-fine-tuning
[6]强化微调文档: https://platform.openai.com/docs/guides/reinforcement-fine-tuning
(文:AGI Hunt)