嚯!大语言扩散模型来了,何必只预测下一个token 人大高瓴&蚂蚁

人大高瓴人工智能研究院与蚂蚁集团提出LLaDA模型,使用扩散模型替代自回归,挑战了大语言模型的固有限制,并在上下文学习、指令遵循和反转诗歌任务中超越GPT-4。
人大高瓴人工智能研究院与蚂蚁集团提出LLaDA模型,使用扩散模型替代自回归,挑战了大语言模型的固有限制,并在上下文学习、指令遵循和反转诗歌任务中超越GPT-4。

清华、中国人民大学与蚂蚁集团联合发布LLaDA模型,采用扩散方式打破自回归垄断,性能媲美Llama 3 8B。该模型颠覆大语言模型认知,采用掩码扩散模型训练范式,实现全局视角生成;在数学问题解答、多轮对话、代码生成等方面表现出色。相关资源包括论文和项目主页。

EMO2 是阿里巴巴通义实验室提出的一个音频驱动人像 AI 视频生成的升级版本,通过一张人物肖像图片和任意长度音频生成流畅自然的手部动作、面部表情及身体姿态。
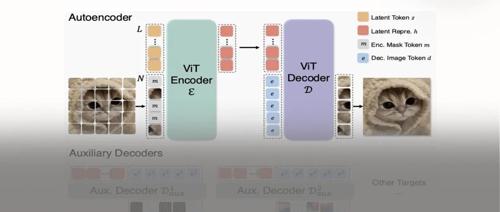
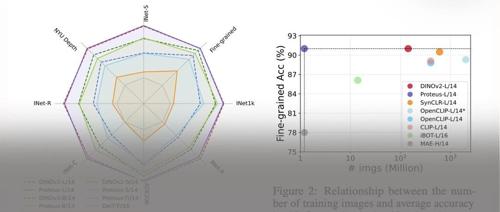
ETok在仅使用128个token的情况下,于256×256和512×512分辨率的ImageNet

来自港中文、北大和上海AI Lab的研究团队将思维链(CoT)与生成模型结合,显著提高了自回归图像生成的质量,并提出了潜力评估奖励模型(PARM)及其增强版本(PARM++),进一步优化了图像生成质量。
《Understanding Deep Learning》是一本关于深度学习的专业书籍,涵盖理论基础、性能评估等多个主题,并附有大量练习题。