通用 Agent 向左,Agentic Browser 向右

Fellou 是全球首个 Agentic Browser,专注于浏览器内的人机协同环境。它支持跨平台搜索、跨网页任务执行和智能感知浏览器环境等功能。尽管存在上手门槛高和执行速度慢等问题,但其GUI Agent技术已达到行业领先水平。
Fellou 是全球首个 Agentic Browser,专注于浏览器内的人机协同环境。它支持跨平台搜索、跨网页任务执行和智能感知浏览器环境等功能。尽管存在上手门槛高和执行速度慢等问题,但其GUI Agent技术已达到行业领先水平。

第42届国际机器学习大会ICML将于2025年7月在加拿大温哥华举行,共收到12107篇论文,接收率为26.9%。313篇论文被选为Spotlight Poster。高分论文包括Neural Discovery in Mathematics等,如字节跳动的MARS和伊利诺伊大学厄巴纳-香槟分校的EmbodiedBench。一些被拒论文同样值得讨论,因为这些论文的价值可能未被充分挖掘。
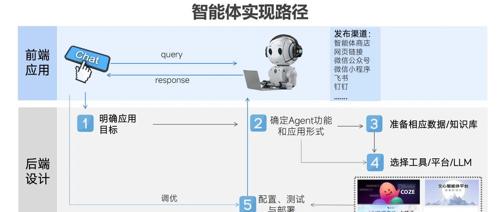
AI Agent成为科技圈新宠。从OpenAI到Google DeepMind都在押注这一全新方向。它能够自主感知、决策和行动。Coze提供零代码智能体搭建平台,助力用户打造个人或企业专属Agent。
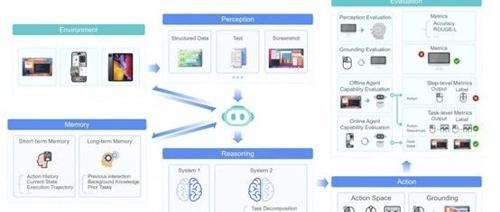
字节跳动开源的多模态AI Agent UI-TARS 1.5在计算机、浏览器和手机使用测试中表现优异,并在GUI定位方面显著提升。它在游戏领域也表现出强大能力,展现出出色的推理、决策和适应能力。
字节跳动新推出Agent产品“扣子空间”,支持无线裂变邀请码获取。用户可通过探索和规划模式生成网页、网页版吉他、天气预报网站等任务,并添加MCP扩展插件。目前处于内测阶段,存在一些小问题,但任务拆解与多模态输出超越多数竞品。

本文深入探讨了Agentic概念,指出其实质仍是经典强化学习(RL)。通过分析字节跳动的VeRL框架和相关实践案例,强调构建高质量、高效能的环境对于推进大模型RL训练的重要性。
字节跳动旗下AI Agent平台‘扣子’开启内测,提供智能任务分解、高效协作等功能。通过60余款插件支持和内置MCP扩展,助力用户完成复杂任务。