


极市导读
本文深入探讨了“Agentic”这一热门概念,指出其本质仍然是经典的强化学习(RL)。通过对字节跳动的 VeRL 框架和相关实践案例的分析,文章揭示了在大模型时代,强化学习依然是实现智能体与环境交互的核心方法,并强调了构建高质量、高效能的环境对于推动 RL 发展的重要性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
序言
agentic是一个最近被炒的火热的概念,什么东西都可以说是agentic的。
举个不恰当的例子,机器人是具身智能,自动驾驶是具身智能,甚至minecraft都是具身智能,我还看见过有人说星际争霸是具身智能的。所以具身智能是什么呢?我也不知道了,反正你说是他就是吧。
对应的agentic也是一样的概念,有人说是原生agent,可原生agent是什么,不清楚。有人说是一种思维,和外界环境交互获取知识,难道以前rl不是这么做的吗?
在这里我们或许可以直接拿rl的定义来看这个问题。agentic就是最典型的决策问题解决方案,通过和环境交互获取信息,执行策略。通过环境的反馈,要么更新神经网络的权重本身,要么更新一些辅助的信息,比如q value, prompt。那我们就可以发现,llm agent本质上是属于bc agent或者 行为树agent一类的,他可以作为rl agent的起始策略来缩减探索空间。经常做rl的人应该熟悉,大部分决策任务就是先从行为树或者behavior cloning 开始的。
介绍完了定义,让我们想想llm/mllm现在发展的趋势。我们已经用完了几乎所有的互联网信息,把人类历史上所有的数据都压缩到了模型之中,现在我们已经只能依靠标注数据和合成数据勉强提升模型的性能了。那么有没有一种方法是自动化产生数据,能够自迭代提升的呢?很显然那就是强化学习,这套与环境交互得到准确reward,并且持续迭代提升的方法。
所以下一个阶段的llm/mllm训练,必然是通过与环境交互获取信息,得到奖励来不断优化。agentic最核心的部分,是如何构建一系列高质量,高效,动态,准确的环境,能够保证模型训练的时候可以高度并行的采集训练。
实践部分
实践部分
实践部分将以字节的verl为例,通过search-r1的复现流程来讲解agentic rl。注意本文不讨论任何算法问题,因为本人不会。
verl框架粗糙分析
首先我们介绍一下verl 框架本身,这个是字节出品的开源LLM 强化学习框架,支持很多算法。按照知乎大佬:从零开始的verl框架解析[1]和【AI Infra】【RLHF框架】三、VeRL中的Rollout实现源码解析[2]的介绍以及我自己的经验来看,vllm本身并不太像一个强化学习框架,感觉就是SFT 框架改吧改吧实现的一个替代版(但还是很好,因为让我写肯定写不出来),或者是他的NLP 味道实在是太浓了。
从RL 的视角看待这个问题,verl本质是对rollout,数据并行做了很好的优化,然后给一个问题就让模型生成对应的答案,最后通过rule base 或者reward model来进行打分即可,这种情况下模型的回复就可以看做是bandit问题,你给LLM 一个问题,然后拉一下杆,如果好,就多学习这个策略,如果结果不好就少学习这个策略。那这样的框架显然很不适合环境交互,首先我交互多次的这个需求就无法满足,然后我们也没有replay buffer,更没办法同时启动很多环境进行测试,同样不利于我们使用各种各样的工具,为此我们需要把代码框架做一些拓展和转换,使其可以和环境交互,获取新的知识。
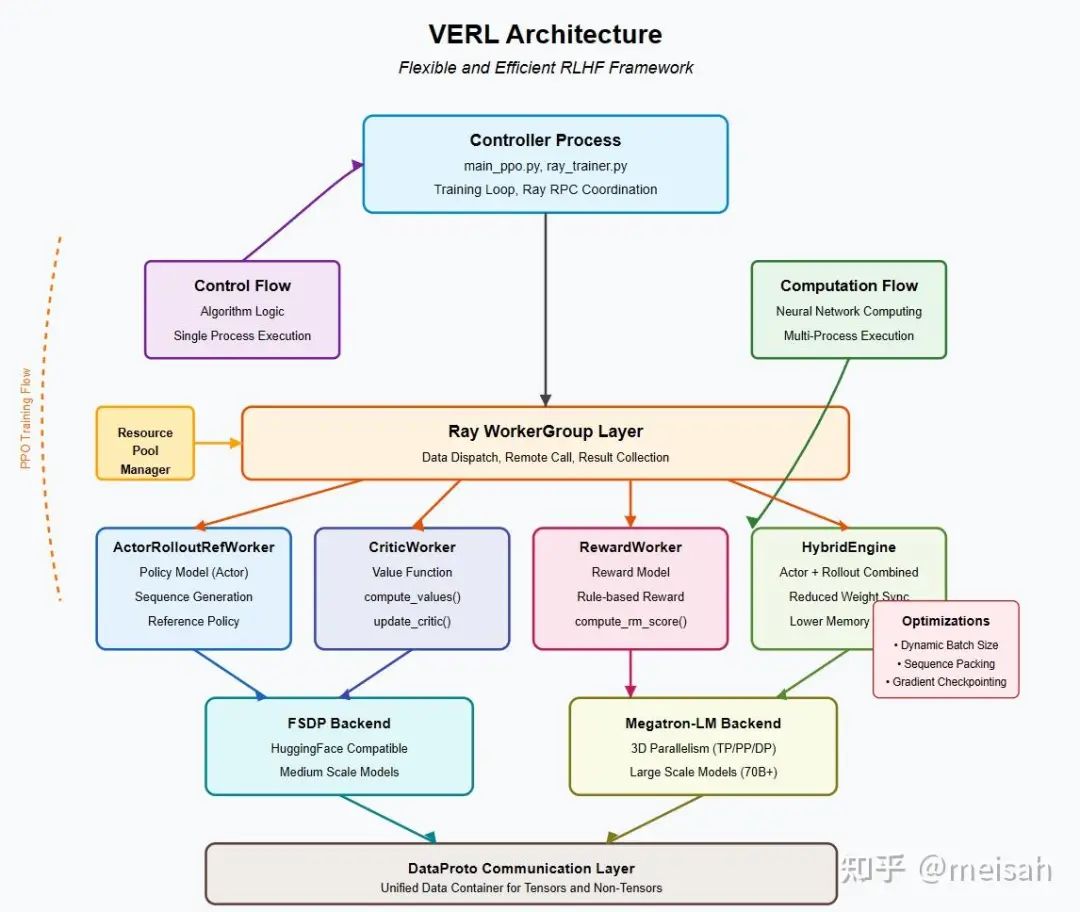
search-r1框架粗糙分析
自从deep research 流行以来,公司和学术界都在尝试复现,个人看了researcher,search-r1 等等代码实现。我总结一下大家的实现方案。我个人认为主要的解决方案就是从rollout端下手,将search tool与环境交互放在vllm rollout 生成回复的那一块,只要模型生成的
-
每个工具实际上我们都得写一个类似的类,而且多工具调用是非常麻烦的。 -
我们实际上并没有分离环境和agent 端,这个问题依然存在,我们不可能随意更换环境或者随意更换agent。 -
rollout端的负担实在是太大了,而且debug太麻烦。
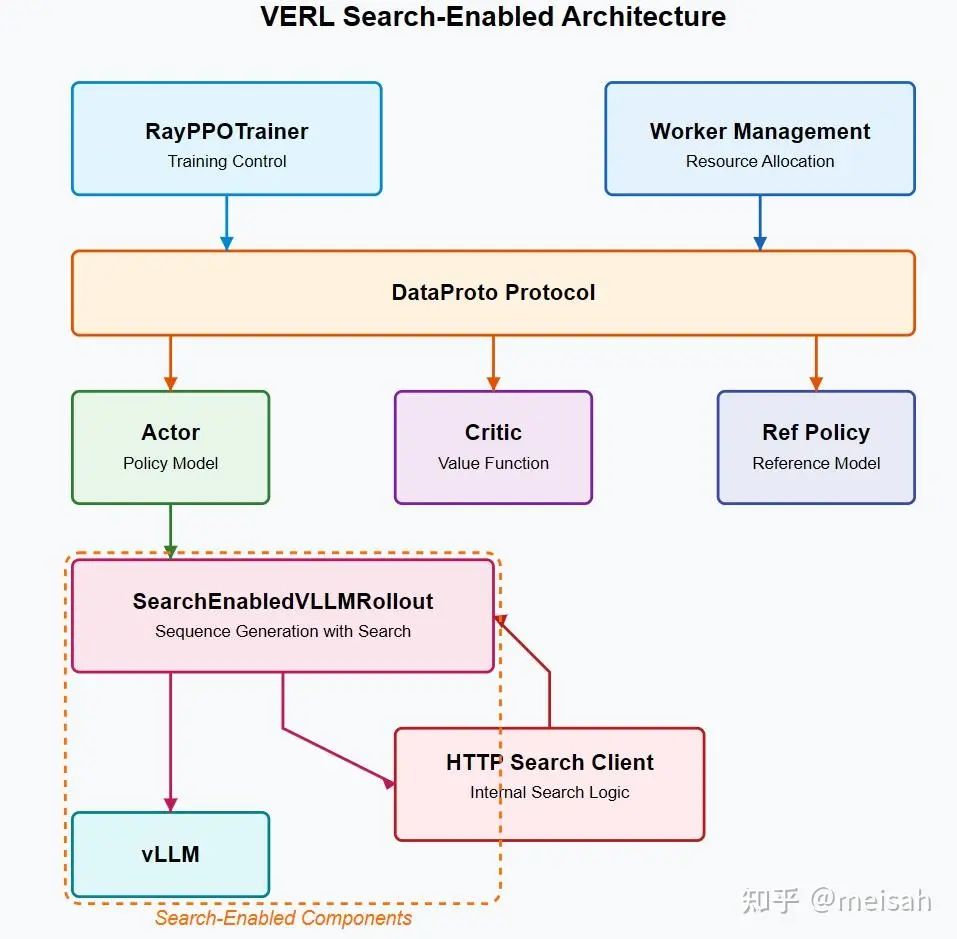
Tool usage框架设想
为此我们又必须设计一种替代的解决方案,能够实现多个工具的调用,同时满足tool 并发和通信的需求。 这里我们一个理想的设计是保留原有的代码不变,专门为tool 设置一个tool worker,然后tool就只需要在tool worker 这里注册一下,vllm rollout本身修改一下能够适配更多tool的special token即可。 那这样我们就可以只通过填参数和注册完成多个工具的调用与适配了。但这里我们也只是解决了一个问题,能够用多个工具了,代码耦合依旧严重,依旧无法实现真正意义上的环境交互。
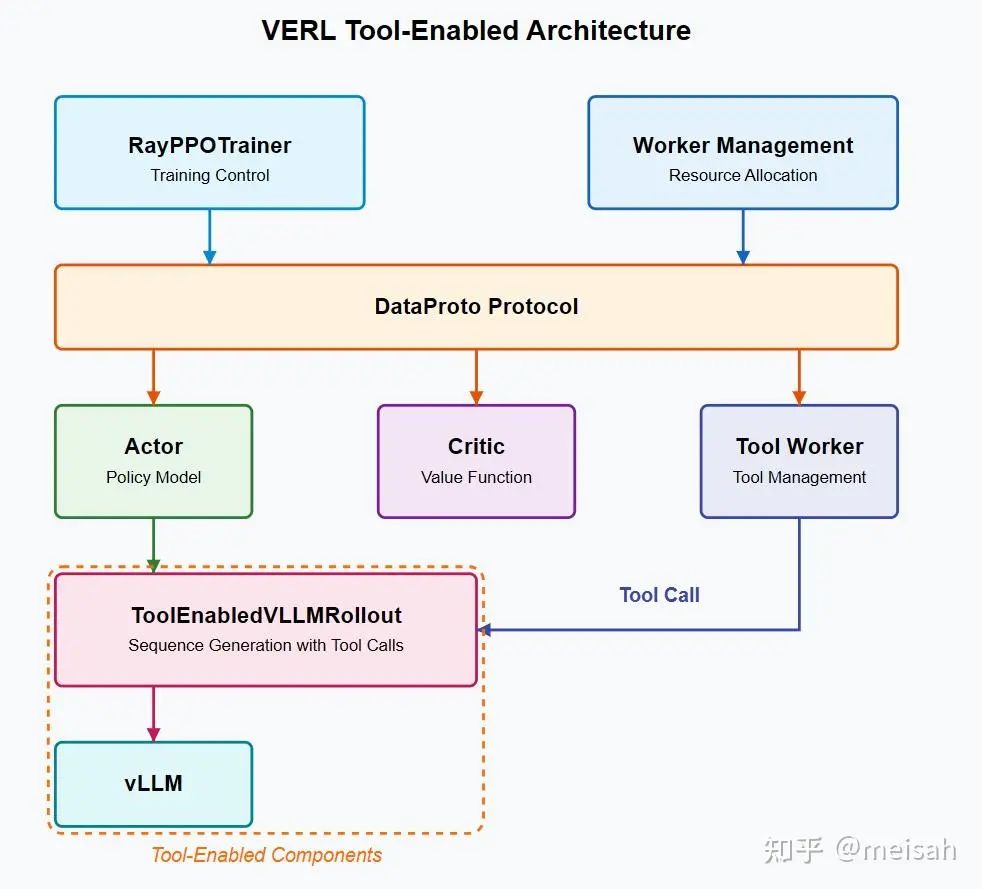
强化学习框架解析
那不如让我们回到梦开始的地方,回到RL 大杀四方的年代来看看强化学习最成功的案例是怎么做的。以alphastar 的强化学习框架为例, 我们发现大规模并行的强化学习训练,也就是impala架构是需要环境,actor,learner分离的架构。同时我们需要注意到,交互的游戏环境数量达到了16k(这是因为alphastar的模型大概300m不到,推理很快,但是星际争霸2 环境很慢)。
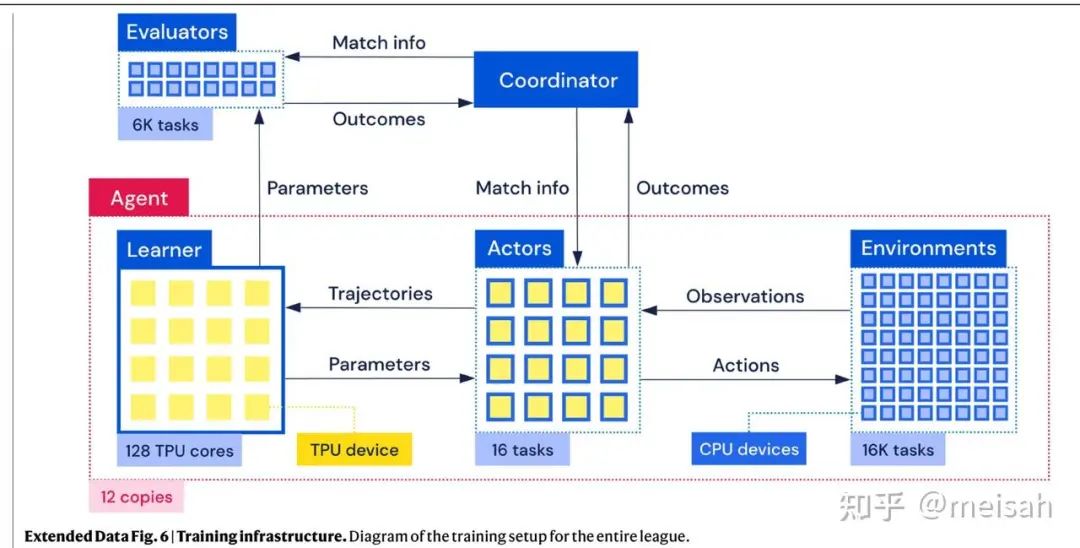
统一框架设想
现在再回顾LLM RL 中需要交互的场景有哪些, 工具调用,游戏引擎,奖励模型,rule-base reward等等,看起来很难统一起来。 但是如果我们LLM视为智能体,而所有LLM与外界的交互都抽象为与环境的交互的话,我们就可以设计出一套符合强化学习的基本范式的框架。
这个统一的环境框架,基于以下关键理念:
-
环境统一抽象:所有外部交互(工具、游戏、奖励模型等)都视为”环境” -
基于Ray Worker实现:利用Ray的Actor模型和分布式能力 -
模块化与可扩展性:便于添加新的工具和环境类型 -
资源隔离与管理:为不同环境提供适当的资源配置
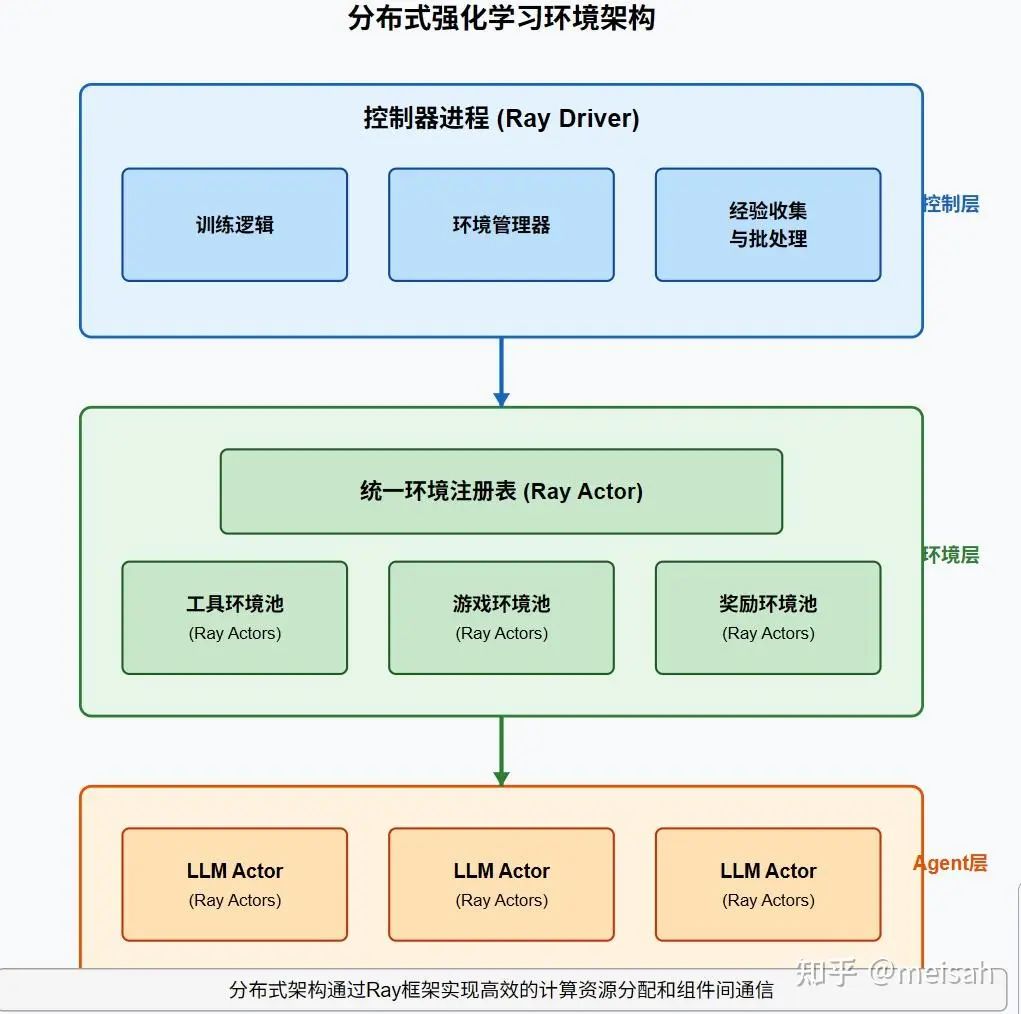
假设大模型是一个活生生的人,那么他调用搜索引擎获取信息,当然是和环境交互了;他打游戏获取输赢,当然是与环境进行交互了;他做题答卷子,根据成绩好坏来改进,这当然也算是与环境交互了。通过这个简单的转换,我们就可以把一切东西统一起来,而这个其实不就是我们说的agentic rl吗?
结语
那最后我们总结一下,所谓的agentic rl,无非就是把以前RL的内容重新搬了出来,放在更多更贴近我们生活的场景中进行训练罢了。 我们做的只不过是把以前RL那些10mb的小模型,替换成了大模型,把以前大家刷分的atari,smac等环境换成了新的benchmark来做。
实践的过程中,我发现核心难点还是在于环境的稳定性和并发性,大多数toy的工作都没办法支撑起500以上的并发,大部分环境也写的完全不行,我们的工作都卡在了如何写一个好环境(工具)上。正如同benchmark推动的cv和nlp的发展,环境也推动了rl的发展,我们的当务之急是需要一批高质量的环境,而不是一堆loss 算的半天飞的算法。
最后放一张大佬的梗图

引用链接
[1]从零开始的verl框架解析:https://zhuanlan.zhihu.com/p/30876678559
[2]【AI Infra】【RLHF框架】三、VeRL中的Rollout实现源码解析:https://zhuanlan.zhihu.com/p/1888310042580743730

(文:极市干货)