
奖励模型


ChatGPT后训练方法被OpenAI离职联创公开,PPT全网转~
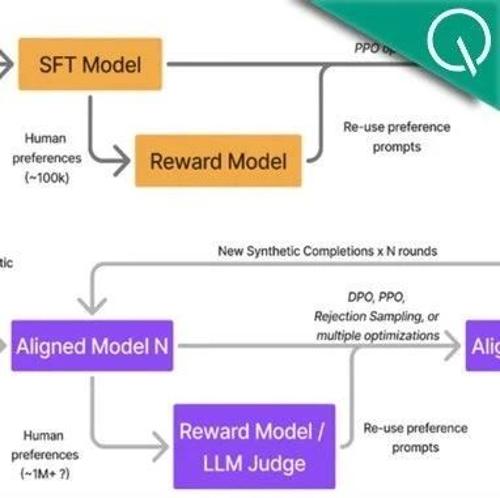
OpenAI前员工John Schulman和Barret Zoph分享了他们在后训练阶段开发ChatGPT的经验,并发布了相关PPT。他们讨论了监督微调、奖励模型和强化学习等关键组成部分,以及如何处理拼写错误和其他挑战。
看DeepSeek R1的论文时,我突然想起了AlphaGo

MLNLP社区介绍了DeepSeek R1论文,并重点提到了基于规则的奖励模型和多阶段训练策略,作者通过与AlphaGo的对比分享了个人见解。文章还提及技术交流群邀请函和MLNLP社区介绍。



让AI眼里有活主动干!清华&面壁等开源主动交互Agent新范式

清华大学与面壁团队开源新一代主动Agent交互范式,使AI具备主动观察环境和提出任务的能力。相比传统被动式Agent,主动式Agent能够预判用户需求并自主帮助解决问题。