
Meta

MoCha:对话角色视频生成神器,开启虚拟创作新时代!

最近Meta与滑铁卢大学联合开发的MoCha模型在对话角色视频生成方面取得了重大突破,能够根据文本或语音输入生成带有同步语音和自然动作的完整角色动画。其创新的技术架构和训练策略使得角色的嘴型能够更加精准地匹配语音内容,增强了动画的真实感和自然度。
Yann LeCun:我不玩大模型了,那都是过去式!

Meta首席AI科学家Yann LeCun表示不再对大语言模型感兴趣,认为它们并非通往真正人工智能的正确路径。他指出大语言模型缺乏理解物理世界的能力,没有持久记忆,并且无法进行真正的推理和复杂规划。
Llama 4在测试集上训练?内部员工、官方下场澄清,LeCun转发

Meta 新发布的Llama 4模型在实战中表现不佳,引发了广泛质疑。尽管其在大模型竞技场上的排名不错,但在实际应用中的效果却不如人意。部分用户反馈称该模型存在多方面的问题,如生成代码、抽象推理等能力不足。为了澄清疑虑,Meta 发布了Llama 4的相关测试数据,并承认之前的宣传策略可能存在问题。

Llama 4爆料大反转,没在测试集上训练!华人员工实名辟谣,LeCun出面救火

Meta针对Llama 4训练作弊的爆料迅速反击,但模型的实际表现却频频被吐槽。Ahmad Al-Dahle澄清不同平台间质量差异是因为开源行为,Yann LeCun力挺模型。尽管存在争议,Llama 4在某些测试中的表现令人失望。
Llama 4多模态大模型上线即开源,测试成绩、开源模式广遭质疑

Meta发布首个原生多模态Llama 4系列模型,性能超越GPT-4。包含Maverick、Scout和Behemoth三个模型,支持1000万token上下文。不过其开源模式存在争议,包括登录Hugging Face账户限制、严格再分发要求及命名要求等。
Meta 你摊上事了!Llama 4 vs DeepSeek:谁才是最强开源模型?
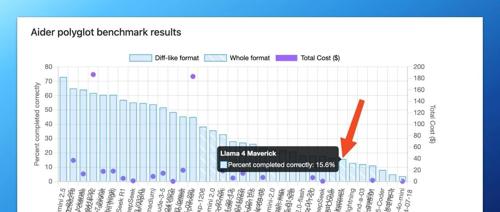
Meta 新发布的Llama 4因基准测试成绩亮眼但遭用户质疑,称其实际表现不佳。Meta 因疑似数据污染技术而受到批评。此外,Meta的Llama 4 Maverick模型在多个任务如前端开发、逻辑推理等方面的表现也不尽人意。
反击DeepSeek失败!Llama 4效果不好,Meta承认有问题

今天凌晨
1
点半,Meta生成式AI领导者Ahmad Al-Dahle在社交平台回应了前天开源的Llama 4被质疑的问题。Meta否认在测试集上进行预训练,并表示会修复漏洞提升模型性能。然而,国内媒体以Meta新开源的Llama 4 Maverick代码能力比肩其V3模型为噱头写标题。Meta随后发布声明,澄清质量差异因优化需要时间,并称不会在测试集上预训练。多位网友质疑Llama 4的实际表现低于预期,认为Meta可能在测试中进行了篡改。
LlaMa 4 翻车了!

Meta 新发布的 LLaMa 4 模型疑似在训练过程中作弊,内部人士爆料团队直接将测试数据集塞进训练数据。AI 界对此事反响强烈,有人质疑 Meta 负责人是否知情,另有声音认为可能只是简单错误所致。