
里程碑,GPT-4.5大模型正式通过图灵测试!
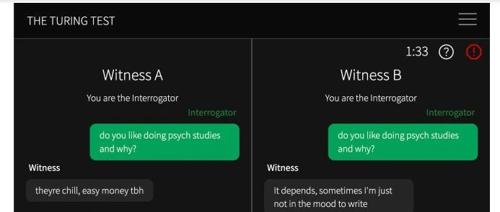
加州大学圣迭戈分校的研究学者首次提供了人工系统通过标准三方图灵测试的实证证据。GPT-4.5和LLaMa-3.1在相同提示下被判断为人类的比例分别为73%和56%,显著高于真实人类参与者被选中的比例,表明这些系统已经非常接近人类智能水平。
加州大学圣迭戈分校的研究学者首次提供了人工系统通过标准三方图灵测试的实证证据。GPT-4.5和LLaMa-3.1在相同提示下被判断为人类的比例分别为73%和56%,显著高于真实人类参与者被选中的比例,表明这些系统已经非常接近人类智能水平。

UC San Diego团队通过实验验证GPT-4.5不仅通过了图灵测试,其表现甚至超过真人。胜率高达73%,远高于对照组人类对手的50%。研究发现人设提示是关键因素。

最近,OpenAI 推出的新模型 GPT-4o 价格高昂且性能升级显著。相比之下,DeepSeek 和谷歌的模型则更加实惠。更新后的 GPT-4o 在性价比、直觉和创造力等方面表现突出,但仍存在编程能力方面的不足。

DeepSeek-V3-0324 新模型发布,参数量6850亿。相比前代,在基准测试中表现卓越,尤其在推理能力、编程能力和中文写作方面有显著提升,并且修复了一些问题。
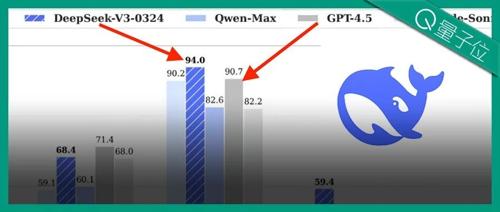
DeepSeek官方发布DeepSeek-V3模型更新技术报告,V3版本参数量约为660B,在数学、代码类评测集成绩超过GPT-4.5,并展示了其在前端开发、中文写作、中文搜索及工具调用等方面的提升。

昨晚,DeepSeek发布新版本V3.0324,参数增至685B,在Hugging Face上开源且MIT许可。其网页生成能力显著提升,实测代码能力与Claude 3.7相当,但超越了Claude 3.7和GPT-4.5的数学能力和编程能力。

文章介绍了一篇关于对抗攻击的研究成果,该研究提出了一种新的方法M-Attack来提高对大型视觉语言模型的攻击成功率,并成功应用于多个商业模型中。

OpenAI再次指控DeepSeek存在重大风险,并要求美国政府采取行动禁用DeepSeek,同时其他国家如意大利、澳大利亚和韩国也对DeepSeek实施了禁令或限用措施。然而,DeepSeek通过开源模型打破了技术垄断,推动了AI普惠,成为人人可用的AI。

腾讯发布混元T1模型,在多项指标上超越GPT-4.5及DeepSeek R1,尤其在文化创意、文本总结和智能体能力方面表现突出。该模型采用创新架构Mamba-Transformer MoE,并实现了极高响应速度与高质量输出。
用一文记录AI大模型领域风云变幻的一月,LiveBench和LMSYS排行榜对比显示,Claude 3.7 Sonnet-Thinking荣登榜首,GPT-4.5紧随其后。LMSYS StyleCtrl排名中,GPT-4.5和Grok 3表现优异。