
AI七个月突破数学家“围剿”反超人类!14位数学家深挖原始推理token:不靠死记硬背靠直觉
大模型o3-mini-high在7个月内从只能答对2%的数学题目提升至答对22%,引发了数学家们对其推理机制和局限性的讨论。研究发现,o3-mini-high依靠广泛的知识储备而非精确证明,并依赖直觉而非严格推导。同时,它缺乏创造力、理解深度以及形式精确性,表现出一定程度的幻觉现象。
大模型o3-mini-high在7个月内从只能答对2%的数学题目提升至答对22%,引发了数学家们对其推理机制和局限性的讨论。研究发现,o3-mini-high依靠广泛的知识储备而非精确证明,并依赖直觉而非严格推导。同时,它缺乏创造力、理解深度以及形式精确性,表现出一定程度的幻觉现象。

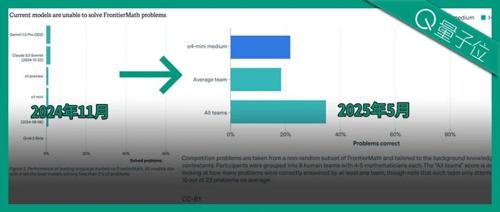
不到两年,o4-mini与40位数学家挑战300道菲尔兹奖级难题,一举击败6组团队,碾压人类平均水平。Epoch AI举办比赛考察AI数学能力进展,结果显示AI在FrontierMath上解决了约22%的题目,而人类总体上解决约35%的题目。未来1-2年内,『超级程序员』和『AI数学家』将取得重大突破。

在FrontierMath基准测试中,O4-mini-medium击败了由数学专家组成的团队。尽管AI尚未达到超人水平,但有观点认为它很快就会超越人类。

OpenAI因在FrontierMath数学基准测试中作弊而陷入风波,被指获得了题库的特权访问权,并资助了该测试。此举引发了业界对于OpenAI领先优势是否真实存在的质疑,同时也暴露了其商业化压力下的困境。
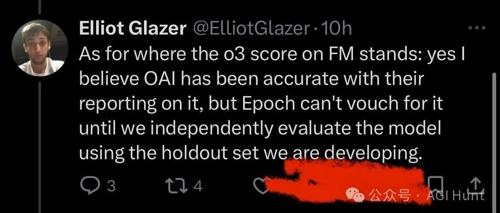
OpenAI再次陷入信任危机,被揭发从一开始就可访问FrontierMath全部数据,引发业界哗然。事件揭示了数据使用、透明度及诚信问题,引发了广泛讨论与质疑。

Epoch Al 在与 OpenAI 合作的 FrontierMath 项目中因透明度问题道歉,并承认沟通失误。他们承诺改进未来的工作。



