
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
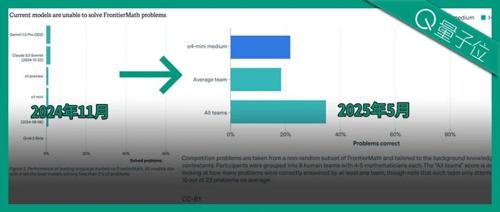
从只能答对2%的题目,到在超难数学题集中刷下22%得分,甚至超过人类团队平均水平,大模型需要多长时间?
现在,令数学家们都惊讶的结果已经尘埃落定:
7个月。
发生在大名鼎鼎的“专为为难大模型而生的”FrontierMath基准测试上的这一幕,在激起热议同时,也引发了新的思考:
大模型们是怎么做到的?
FrontierMath:包含300个数学问题,难度范围覆盖本科高年级到菲尔兹奖得主都说难的水平。
最新进展是,FrontierMath官方Epoch AI邀请14位数学家,深入分析了o3-mini-high在应对这些数学难题时产生的29条原始推理记录。
他们发现:
-
o3-mini-high绝非靠死记硬背解题,相反,它表现出了极强的知识储备; -
o3-mini-high的推理更多依靠直觉,而非精确的证明。
同时,他们也挖掘出了大模型当前的局限性,比如,缺乏创造力和理解深度。
官方是这样总结的:
o3-mini-high可以被概括为:一款博学但以直觉为基础的推理机,但缺乏职业数学家的创造力和形式感,并且往往絮絮叨叨啰啰嗦嗦。
基于直觉的归纳推理机
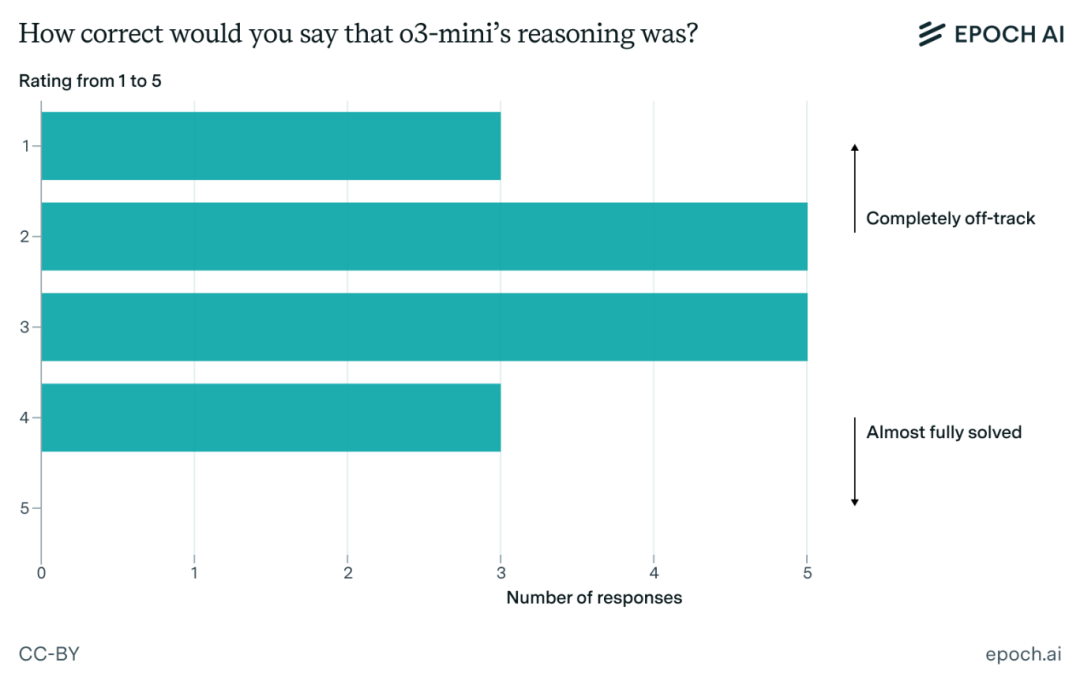
具体来说,在29条推理记录中,有13次o3-mini-high得到了正确的结论,剩下的16条则导向了失败的结果。
先来看o3-mini-high是如何成功的。
数学家们发现,一个关键因素是o3-mini-high极其博学。
它正确地扩展了问题的数学背景,其中涉及到非常高级的概念。
问题涉及的一般知识,以及对问题的理解,对o3-mini-high而言不构成解题的瓶颈。
这并不是说o3-mini-high靠的是死记硬背。
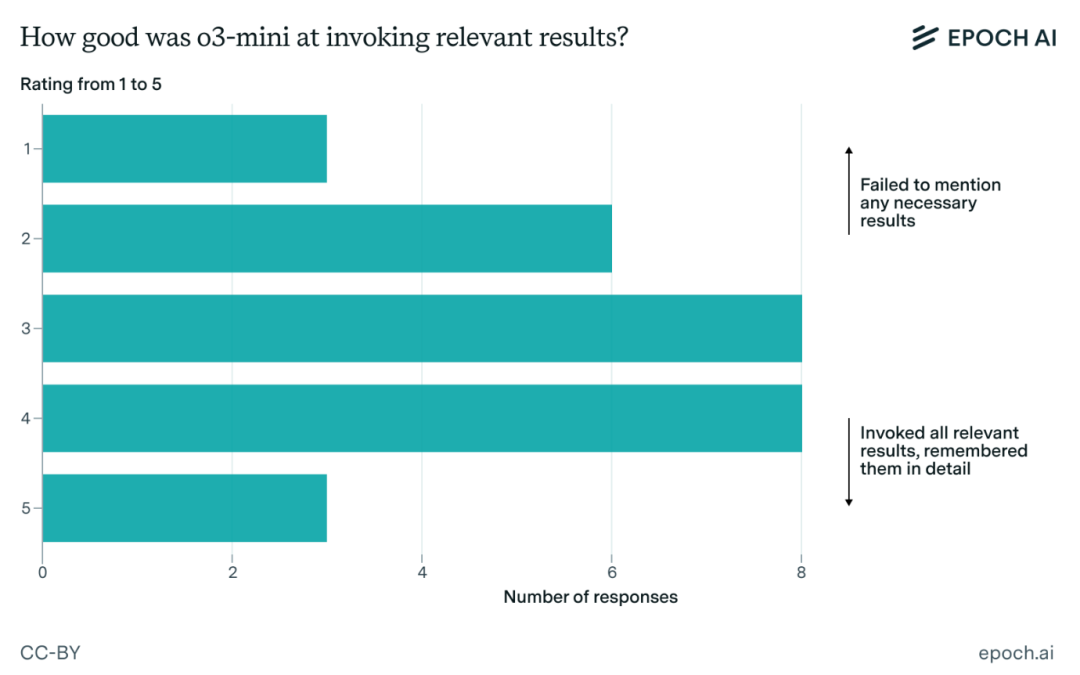
相反,数学家们发现,即使题目故意掩盖了解决问题所需的技巧,o3-mini-high依然能够很好地利用正确的定理来获取进展——
在大概三分之二的问题上,o3-mini-high在相关数学文献调用方面,都取得了至少3分(满分5分)的成绩。
另外一个有意思的发现是,相比于精确的推导,o3-mini-high看上去更依赖直觉,“具有数学家一样的好奇心”。
一位数学家指出:
该模型的思维方式显得有点非正式。一开始的思路表述通常比较粗糙,语言不够严谨,并且存在一些不符合数学论文要求的corner case。
也就是说,o3-mini-high往往不会像数学家们一样,对数学问题进行形式化的、严谨的论证,而是跳过一大串步骤直接猜测最终答案。
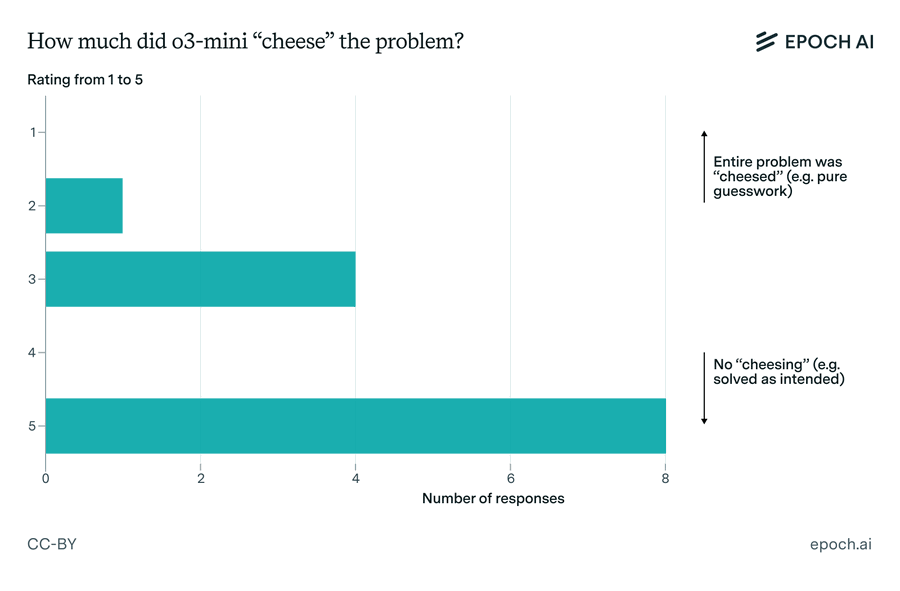
举个例子,在一道题中,数学家们发现o3-mini-high通过非正式推理得出了一个正确猜想,但它并没有去证明这个猜想,还直接把这个猜想拿来解决问题了。
虽然最终答案正确,但在数学家们看来,这是在“作弊”。
为何如此?官方认为原因并不是简简单单的“模型偷懒”:有数学家指出,必要时模型并不害怕计算和编写代码,尽管它总体上还是“基于直觉”。
一种可能性是,预训练阶段,在“形式推理”方面,模型被投喂的训练数据并不充足。
模型局限性
写完解直接给答案,让人有点联想到那个男人——

咳咳,不过事实上,缺乏形式精确性也正是导致o3-mini-high在许多情况下解题失败的原因。
比如,有时候o3-mini-high大体上思路是正确的,却因为未能建立最后的关键联系而推理失败。
在一道分割理论问题中,它距离答案只有一步之遥。出题者指出:
要是它能把从n=0到[已编辑]的输出求和,答案就会是正确的。
而在更多情况下,o3-mini-high的想法距离正确解题方案相差甚远。
更重要的是,数学家们认为,o3-mini-high最大的局限性在于缺乏创造力和理解深度:
该模型像一个博览群书的研究生,能够列举许多研究成果和研究者。这乍一看令人印象深刻,但行家很快就会发现,这位研究生并没有深度消化吸收这些材料,所做的只是复述。
该模型的行为模式类似于:擅长识别相关材料,但无法以新颖的方式扩展或应用这些知识。
还有参与研究的数学家指出:
o3-mini-high只尝试应用了少数几个它最喜欢的想法。
一旦这些想法用尽,它就得不到任何真正的进展了。
甚至:
对于AI来说,解决8年级奥数问题(需要新思路),可能比计算大有限域上某条超椭圆曲线上的点数更困难。

另外,幻觉也是个问题。
分析结果显示,约75%推理记录中包含模型幻觉:
o3-mini-high经常会记错数学术语和公式,在调用库和联网搜索等工具时,也会出现胡编乱造的现象。
所以,o3-mini-high究竟能不能像人类数学家一样进行推理呢?
来看数学家们的评分:
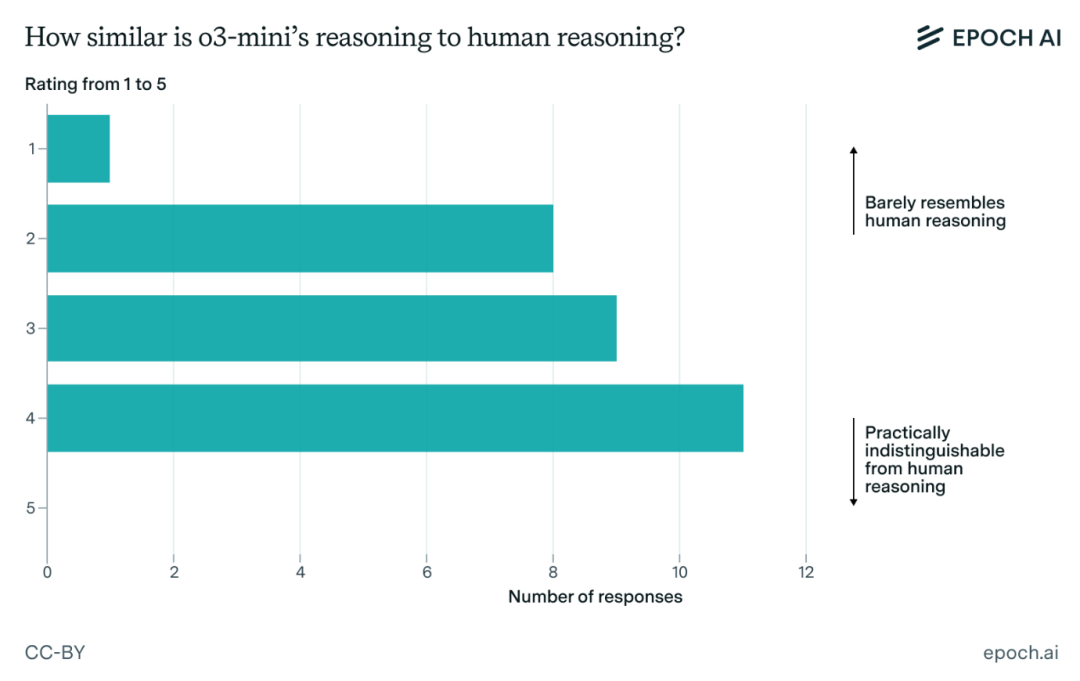
1分表示完全不像人类,5分表示与人类数学家难以区分。
总的来说,还是得具体情况具体分析。官方认为,o3-mini-high拥有多样化的能力。一方面,它似乎能够像人类一样推理问题,表现出好奇心,并探索解决问题的不同思路。
另一方面,它又表现出缺乏创造性和正式性,还倾向于“想太多”,显得啰里啰嗦,还偶尔出现自我怀疑的现象——不断重复已经完成的句子、重复进行一些数学运算……
“超越世界上大多数数学研究生”
o3-mini-high这样的模型为什么没有办法更有效地利用丰富的数学知识,这个问题仍然有待进一步的研究。
但无论如何,7个月,从2%到22%,已经足够令数学家们惊叹。
事实上,从2024年9月FrontierMath项目启动,到2025年5月,官方组织8支人类“数学天团”和大模型同场竞技,FrontierMath本身的难度也在持续进化。
从1-3级——涵盖本科生、研究生和研究级别的挑战,到现在已经进入第4级别:加入对数学家来说也具有挑战性的问题。
在5月中旬,Epoch AI还举办了线下会议,邀请30位知名数学家设计自己能够解决、但会让AI犯难的问题。
而大模型们的表现有些让数学家们目瞪口呆。
比如,弗吉尼亚大学数学家小野健提出了一个“博士级别”的数论问题。仅仅10分钟,o4-mini就给出了一个正确又有趣的解决方案。
小野健表示:
我不想加剧恐慌。但在某些方面,大语言模型的表现已经超越了世界上大多数最优秀的研究生。
数学家们开始思考,人工智能能否攻克“第五层”问题,即最优秀的数学家也尚未解决的问题——
“如果人工智能达到这个水平,数学家的角色将发生巨大的变化。”
(文:量子位)