


论文标题:
PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
论文链接
https://arxiv.org/pdf/2507.06415
一句话理解:
本文介绍了一种名为 PERK(Parameter Efficient Reasoning over Knowledge) 的方法,用于在长文本上下文中进行推理(long-context reasoning)。该方法通过在测试时对轻量级模型适配器(adapter)进行梯度更新,将长输入上下文编码到模型参数中,从而有效地解决长文本推理问题。以下是文章的核心内容:
研究背景
长文本推理的挑战:长文本推理需要从大量、可能嘈杂的上下文中准确识别相关信息。现有的大型语言模型(LLMs)在处理长文本时面临挑战,因为长文本包含更多无关信息,并且可能涉及更复杂的推理问题(如多跳推理),这会降低模型的推理性能。
现有方法的局限性:以往的研究通过测试时学习(test-time learning)将上下文直接编码到模型参数中,但这些方法在训练时需要大量的内存,限制了它们在长文本设置中的应用。

PERK 方法
核心思想:PERK 提出了一种可扩展的方法,通过在测试时对轻量级适配器进行梯度更新,将长输入上下文编码到模型参数中。这种方法在训练阶段使用两个嵌套的优化循环:
内循环(Inner Loop):将上下文编码到低秩适配器(LoRA)中,作为基础模型的参数高效记忆模块。
外循环(Outer Loop):学习使用更新后的适配器从编码的长上下文中准确回忆和推理相关信息。
内存优化:为了降低训练时的内存开销,PERK 采用了截断梯度展开(truncated gradient unrolling),只在最后几步内循环更新中进行反向传播,从而减少了内存需求。
创新点
参数高效:通过仅优化轻量级适配器,而不是整个模型参数,显著降低了训练时的内存需求。
长文本推理能力:通过测试时学习,能够有效地将长文本上下文编码到模型参数中,解决了传统方法在长文本推理中的局限性。
泛化能力:PERK 在未见过的长上下文长度上表现出良好的泛化能力,为长文本推理任务提供了一种实用的解决方案。
实验与评估
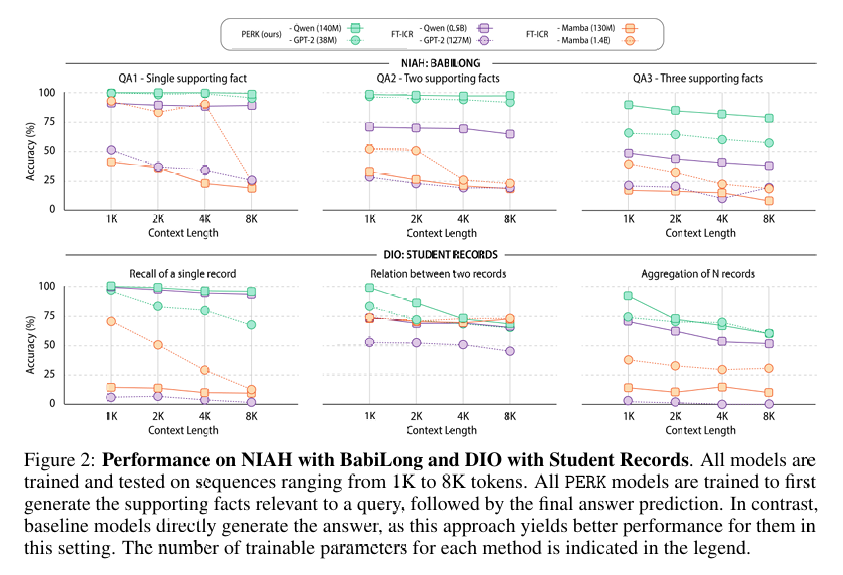
数据集:作者在多个长文本推理任务上评估了 PERK 的性能,包括 Needles-in-a-Haystack (NIAH) 和 Drops-in-the-Ocean (DIO) 两种设置。
NIAH:类似于在长文本中寻找“针”,目标信息与周围无关信息在风格上有显著差异。
DIO:目标信息与无关信息在分布上相似,增加了识别关键事实的难度。
性能对比:
PERK 在所有测试任务中均显著优于传统的基于提示(prompt-based)的长文本推理基线模型。
对于较小的模型(如 GPT-2),PERK 的性能提升可达 90%;对于较大的模型(如 Qwen-2.5-0.5B),性能提升可达 27%。
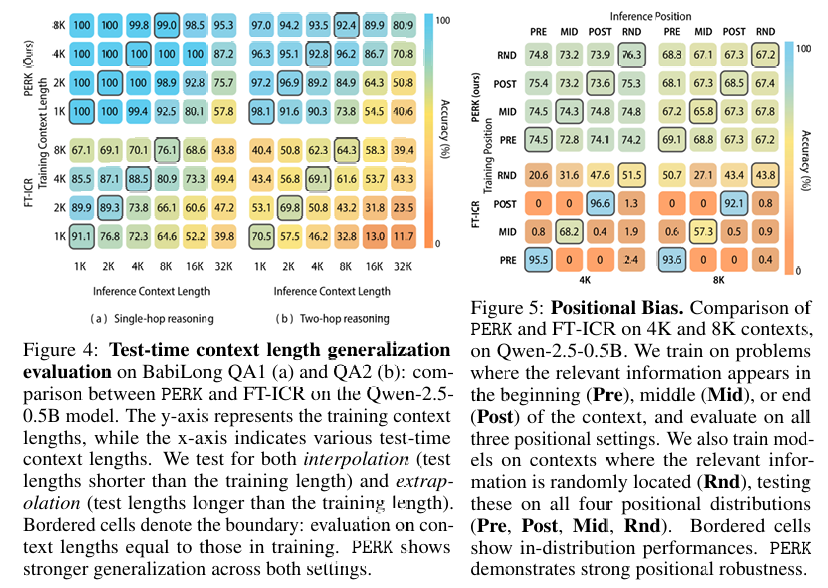
PERK 在推理复杂性、长度外推和相关信息位置变化方面表现出更强的鲁棒性。
推理效率:尽管 PERK 在训练时内存需求较高,但在推理时比基于提示的长文本推理方法更高效,尤其是在处理极长上下文(>32k tokens)时。
结论
性能提升:PERK 在长文本推理任务中表现出色,显著优于传统方法。
泛化能力:PERK 在测试时能够很好地泛化到未见过的长上下文长度,甚至能够处理比训练时长 32 倍的上下文。
位置鲁棒性:PERK 对相关信息在上下文中的位置变化表现出更强的鲁棒性。
推理效率:PERK 在推理时对极长上下文的处理效率更高,具有更低的内存占用和更快的运行时间。
(文:机器学习算法与自然语言处理)