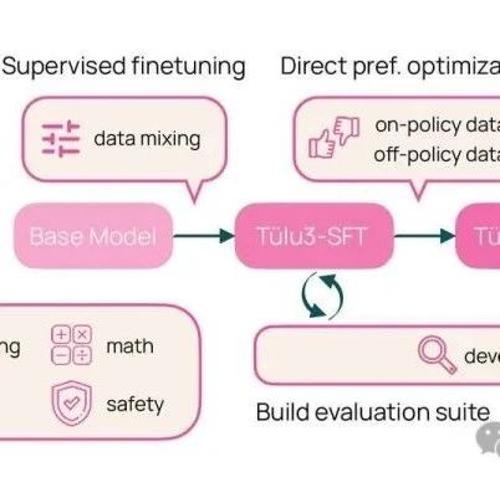
强化学习被高估!清华上交:RL不能提升推理能力,新知识得靠蒸馏 2025年4月26日16时 作者 新智元 奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高