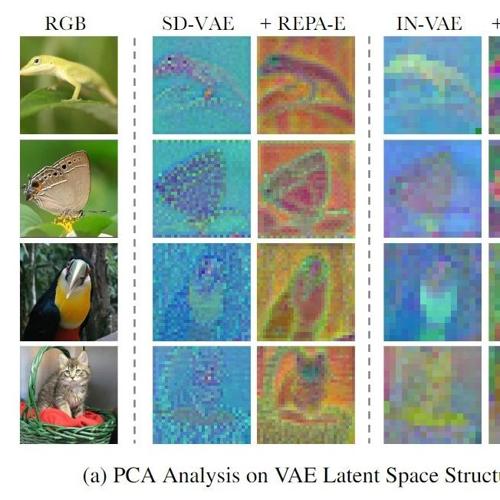
训练扩散模型其实比你想象的更简单!何恺明团队新作Dispersive Loss:给扩散模型加正则化

型参数、无需额外数据,即插即用的正则化技术超简单实现性能提升。
>>加入极市CV技术交流群,走在计算
型参数、无需额外数据,即插即用的正则化技术超简单实现性能提升。
>>加入极市CV技术交流群,走在计算

近日,谷歌推出Gemini Robotics On-Device模型,作为一款面向双臂机器人的通用基础模型,具备通用灵巧操作能力和任务泛化能力,并能在本地离线运行,适用于对延迟敏感的应用场景。

研究提出了一种新的训练框架,让大模型自主设计和优化AI算法,显著减少人类干预。通过经验学习范式,7B参数的大模型ML-Agent在9个任务上持续探索学习,最终超越了671B规模的智能体。

Qwen3 Embedding系列发布,支持多语言文本表征、检索与排序任务。8B版本性能卓越,在MTEB多语言Leaderboard榜单中排名第一。支持0.6B/4B/8B三种尺寸,已在Hugging Face等平台开源。主要亮点包括泛化性强、架构灵活及自定义特性等。

本文提出ZeroSearch框架,无需真实搜索引擎即可激活大语言模型搜索能力。通过轻量级监督微调将LM转为检索模块,并采用课程学习逐步降低文档质量来激发推理能力,显著降低训练成本和提高性能。