AI仅凭“自信”学会推理,浙大校友复刻DeepSeek长思维链涌现,强化学习无需外部奖励信号
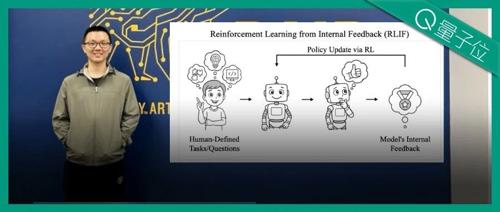
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。
UC Berkeley团队提出的新方法Intuitor通过优化模型自身的置信程度来提升大模型的复杂推理能力,无需外部奖励信号或标准答案。与传统强化学习相比,Intuitor能有效减少无效响应并提高模型在数学和代码生成任务中的表现。

2025年5月28日,北京晴。文章探讨了从几张图看RAG及Agent的问题和基于自我置信度作为强化学习监督信号的工作,强调实际业务数据的重要性,并指出不要过度依赖Agent智能体解决问题。