
多模态后训练反常识:长思维链SFT和RL的协同困境

华为与香港科大研究发现,在多模态视觉语言模型中,长思维链监督微调(Long-CoT SFT)和强化学习(RL)的组合表现不佳甚至互相拖后腿。研究提出难度分类方法,并构建了精细多模态推理榜单数据集来探究不同组合策略的效果。
华为与香港科大研究发现,在多模态视觉语言模型中,长思维链监督微调(Long-CoT SFT)和强化学习(RL)的组合表现不佳甚至互相拖后腿。研究提出难度分类方法,并构建了精细多模态推理榜单数据集来探究不同组合策略的效果。

CMU研究发现,仅用监督微调训练的大模型在其他通用任务上的表现有限甚至退步。强化学习微调的模型则能更好地将数学能力迁移到推理和非推理任务上,预示着强化学习可能是实现可迁移推理的关键方法。

MiniMax提出的新框架V-Triune能够实现视觉任务的统一强化学习,通过三层组件设计和动态IoU奖励机制弥补了传统RL方法无法兼顾多重任务的空白。
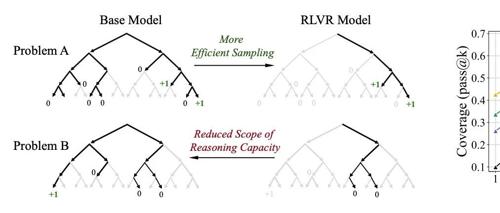
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。