

henry 发自 凹非寺
量子位 | 公众号 QbitAI
学好数理化,走遍天下都不怕!
这一点这在大语言模型身上也不例外。
大家普遍认同:具备更强数学能力的模型往往也更智能。
但,常识就是用来打破的。
最近,来自CMU的团队发现,一些数学好的模型并没有将它们的“天赋”带到其他更加通用的领域。
研究发现,只有用强化学习(RL)训练的模型才能将数学推理技能广泛迁移到其他任务上。而用监督微调(SFT)训练的模型则表现出有限的迁移甚至没有迁移。

网友直呼:又一个苦涩的教训(bitter lesson)。
这数学题,不做也罢?
很明显,人们训练大模型并不只是让它来做数学题的。
研究者之所以热衷于提高模型的数学表现,是因为希望它能够把数学那里学到的严密逻辑应用到其他更广泛的领域。
但在此之前,我们有必要知道,对于一个大模型,专门优化数学推理(math reasoning),它在其他任务(推理任务、非推理任务)上会变得更好,还是更差?
换句话说:做数学推理训练,会不会帮助或者损害模型在其他领域的能力?
为了解决这一疑问,研究评估了20多个模型在数学推理、其他推理任务(包含医学推理、医学推理、智能体规划)和非推理任务(包含常识对话和遵循指令)上的表现。
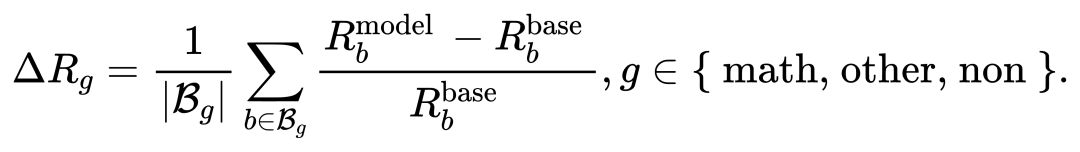
实验先计算模型在每个benchmark任务上相比基线模型(Qwen3-14B-Base)的性能提升幅度,再将这个提升除以基线模型在该任务上的分数,以此得到相对提升的百分比,最后对同一组内所有任务的相对提升求均值,得到该任务组整体的相对增益。
为了更好地定量评估这个“迁移能力”,研究还提出了迁移能力指标(Transferability Index,TI)。
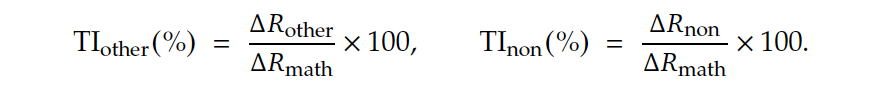
通过“其他推理”或“非推理”任务组的相对增益,分别除以数学任务组的相对增益。这样,TI就清晰反映了数学能力的提升在多大程度上能迁移到其他领域。
如果TI大于0,说明对其他任务有正迁移效应,若小于0,则意味着负迁移。
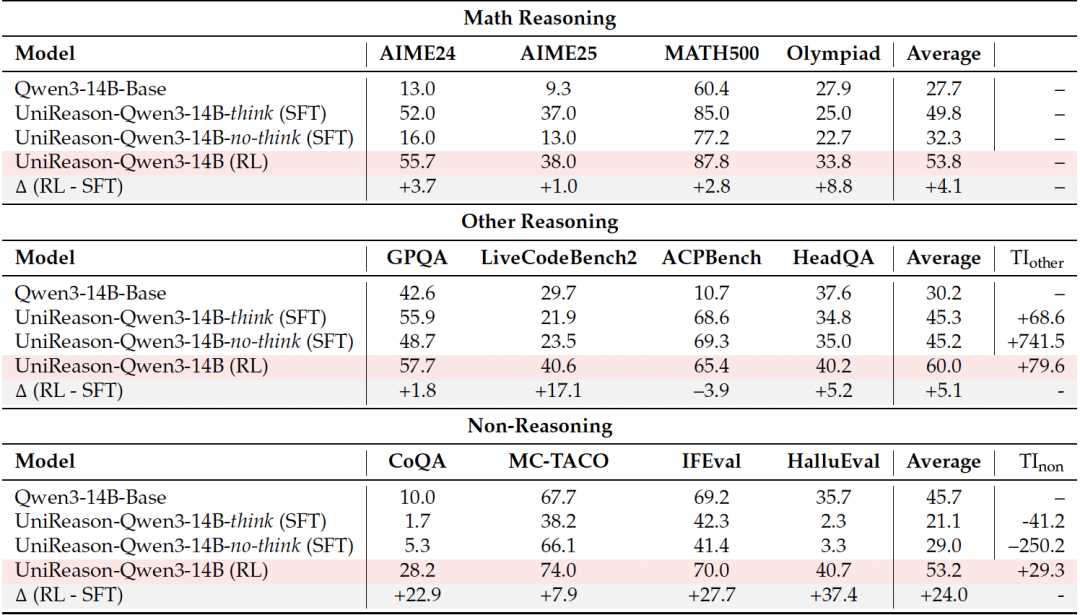
实验结果表明,模型的迁移能力与微调方法、模型规模以及架构有关,但其中微调方法是最关键的因素。
具体而言,采用RL微调的模型,在其他推理任务和非推理任务上都能持续获得更高的迁移能力指标,而使用SFT的模型则往往在非推理任务上出现负迁移。
再进一步的对照实验中,研究采用相同数据集和基线模型验证了在其他条件完全一致的情况下,纯粹因为微调方式的不同,才产生了性能和迁移能力的显著差异。
RL的又一次胜利
为了理解不同微调方法在迁移能力上产生差异的原因,研究进一步探索了模型内部的表征,将特定领域的查询和答案分别输入到基础模型和微调模型中,并对隐藏层表示(hidden representations)进行PCA偏移分析。
通俗来说,通过PCA偏移分析,就能够得知模型在后训练阶段,究竟是既保留了原有的知识,又在具体领域变得更强了,还是学了新的就忘了旧的。
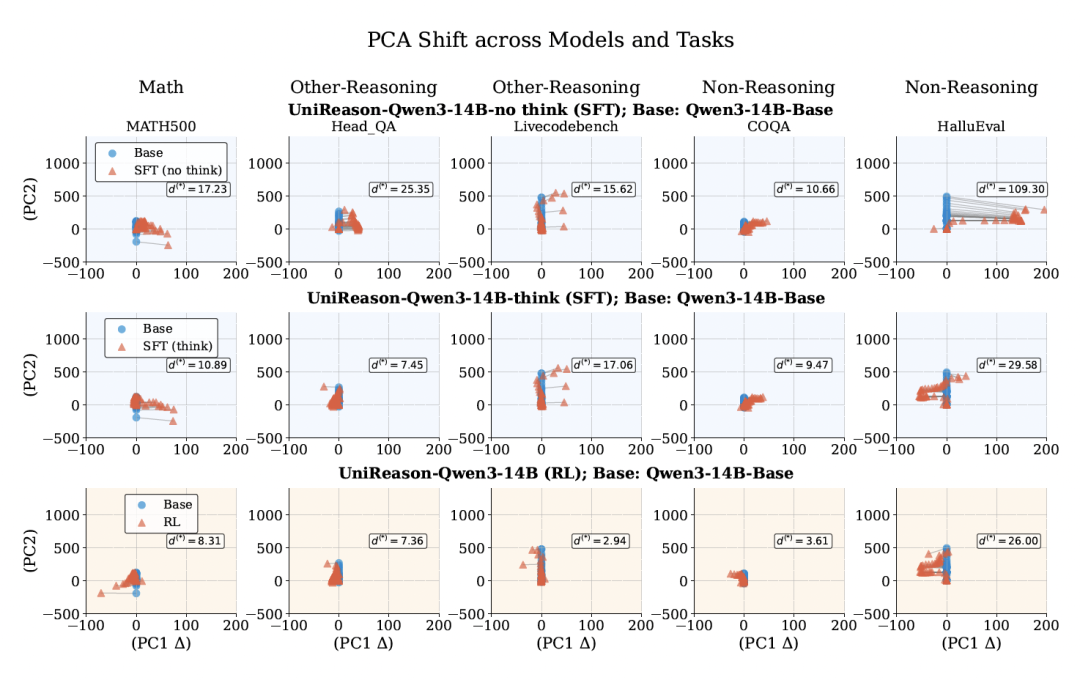
PAC分析表明,RL微调模型在表征空间上的偏移最小。这就意味着,相较于SFT,采用RL进行微调的模型在提升专门领域表现的同时,还保留了之前学习到的能力。

同样的,Token分布偏移分析表明RL训练选择性地调整了逻辑结构词条。而SFT会同时扰乱逻辑和不相关的词条,从而可能损害泛化能力。
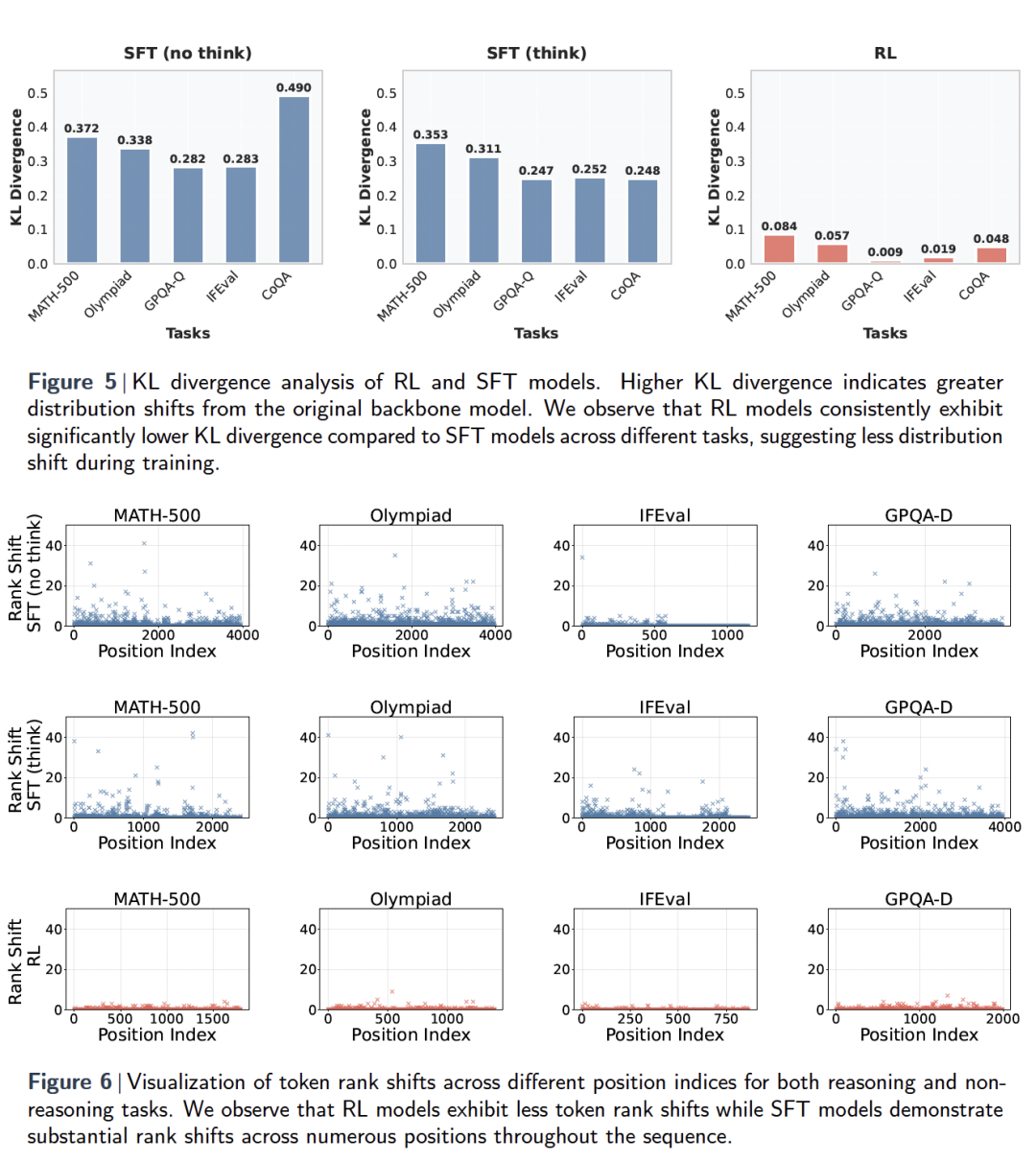
此外,RL模型在推理和非推理任务上的KL散度均显著低于SFT模型(KL散度越高,偏移越大)。
这表明,在Token概率分布层面,RL相比SFT发生的分布偏移更小。同时,RL还表现出更低的Token排名偏移(tokenrankshift)。
由此,相较于SFT,RL够带来更具体、更稳定、更精准的表征更新,从而实现更强的迁移能力与泛化性。
RL实现了它在LLM的又一次胜利,也预示着强化学习似乎是真正实现可迁移推理发展的关键。
论文地址:
https://arxiv.org/abs/2507.00432
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
(文:量子位)