
突发!传智元机器人联合创始人 “ 闫维新 ” 将离职

闫维新博士即将离职智元机器人,因资源聚焦教育领域。曾任上海交通大学机械与动力工程学院博士生导师、教授及首席科学家。长期从事机器人研究,主导多项国家级科研项目。
闫维新博士即将离职智元机器人,因资源聚焦教育领域。曾任上海交通大学机械与动力工程学院博士生导师、教授及首席科学家。长期从事机器人研究,主导多项国家级科研项目。

最近在「观猹」平台上,又又又又又上新了超多有意思的 Agent 产品。观猹为每位产品经理员准备了一些邀请码。介绍了 SciMaster、CodeBuddy IDE、Trae Solo 等5款新品。

人工智能与科学研究的深度融合正重塑科学发现边界。上海交通大学-深势科技联合发布的SciMaster作为全球首款通用科学智能体,通过并行化处理加速科研流程,并结合科学基座大模型Innovator优化信息理解和处理能力。

论文提出Dinomaly方法,通过简化模型和创新技术解决了多类别异常检测中的性能问题。模型在多个数据集上达到SOTA表现,首次让多类统一模型超越单类专用模型,具有优异的可扩展性和易用性。

上海交通大学朱怡飞教授团队提出LLMSched调度框架,通过引入三类新节点和贝叶斯网络实现复合LLM应用的高效调度,相较于现有调度器平均任务完成时间降低14~79%。

扩散语言模型(dLLMs)因并行解码、双向上下文建模和灵活插入masked token而备受关注。然而,上海交通大学等团队在最新研究中指出,dLLMs存在根本性架构安全缺陷,几乎毫无防御能力。DIJA攻击无需训练或改写模型参数,就能生成有害内容,并揭示了扩散语言模型的弱点,为dLLMs的安全研究拉开序幕。

上海交通大学和清华大学的研究人员开源了PFLlib代码库,包含多种联邦学习算法、数据集及工具,旨在降低初学者门槛并提供统一实验环境。该库囊括39个算法、3大类场景和24个数据集,并支持GPU资源需求少的500个设备同步训练场景。
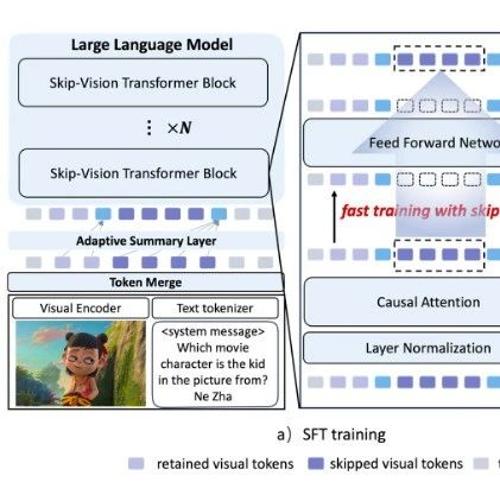
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,该框架通过训练阶段的Skip-FFN和推理阶段的Skip KV-Cache机制减少视觉Token的冗余计算与保留关键信息,实现多模态模型在精度和效率上的双重优化。

近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。

Meta 以超过2亿美元薪酬挖走苹果AI高管Ruoming Pang,刷新顶级AI人才估值认知。苹果内部讨论是否引入OpenAI或Anthropic的大模型,Pang领导的团队因推进自研模型而与管理层出现分歧,最终导致离职。