谷歌“世界模拟器”深夜上线!一句话生成3D世界,支持分钟级超长记忆

谷歌DeepMind发布新一代通用世界模型Genie 3,支持720P画质、每秒24帧实时导航和分钟级一致性保持。Tejas Kulkarni体验后评价其通用性强且能学习物理特性。Genie 3现已以研究预览形式发布,并展示在雅典风格建筑中漫步的场景画面中物体能够保持一致。
谷歌DeepMind发布新一代通用世界模型Genie 3,支持720P画质、每秒24帧实时导航和分钟级一致性保持。Tejas Kulkarni体验后评价其通用性强且能学习物理特性。Genie 3现已以研究预览形式发布,并展示在雅典风格建筑中漫步的场景画面中物体能够保持一致。
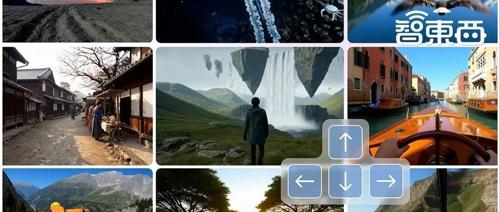
谷歌DeepMind发布的Genie 3是首个支持实时交互的通用世界模型,能生成逼真、一致的720p分辨率3D环境,支持天气变化和新角色操作,并用于测试未来Agent训练兼容性。但目前仍存在行动空间有限、与其他Agent交互复杂、无法精确模拟真实位置等局限性。

硅谷三巨头同日发布新模型,OpenAI开源两款参数量接近o4-mini的GPT-oss模型;DeepMind推出Genie3世界模型实现实时交互和高一致性场景;Anthropic发布Claude Opus 4.1,提升智能体任务及编程能力。

Anthropic发布Claude Opus 4.1,编程性能提升74.5%,在SWE-bench上超越Gemini 2.5 Pro和o3。客户反馈表示Opus 4.1能精准定位修复代码bug,模型无害回复回应率达到99.06%。

北大团队发表综述《Towards Efficient Privacy-Preserving Machine Learning》,系统梳理隐私保护机器学习领域的协议、模型和系统优化,提出跨层次协同设计与优化的重要性。

新智元报道,OpenAI、谷歌和Anthropic发布不同模型。Anthropic发布Claude Opus 4.1,在编码性能和功能上有所提升。对比测试中Claude Opus 4.1表现优于Gemini-2.5-pro等模型,但需谨慎使用较弱的OpenAI-OSS-120B。

Anthropic发布新模型Claude Opus 4.1,相比前一代在智能体任务、真实世界编程和推理能力上有所提升。Claude Opus 4.1现已面向多个用户开放使用,并提供了详细的API定价信息。

谷歌DeepMind发布第三代通用世界模型Genie 3,可以生成实时交互式环境,实现实时导航、一致性和高分辨率。其突破包括实时性能、长时程一致性以及可提示的世界事件能力。