OpenReasoning-Nemotron:NVIDIA发布一系列蒸馏推理大语言模型
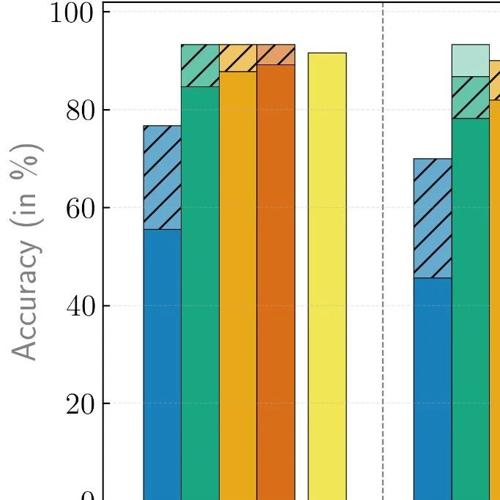
NVIDIA发布OpenReasoning-Nemotron系列推理大模型,涵盖多种规模的数学、科学与代码领域模型,性能领先且支持多代理生成和GenSelect方案优化解题准确性。
NVIDIA发布OpenReasoning-Nemotron系列推理大模型,涵盖多种规模的数学、科学与代码领域模型,性能领先且支持多代理生成和GenSelect方案优化解题准确性。
Claude Agent介绍了一种智能Agent系统,支持灵活多样的工作流,与Obsidian完美结合,推荐Max订阅计划和相关工具以提升工作效率。
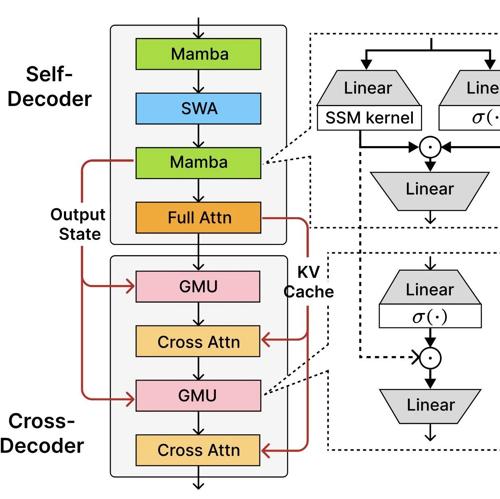
ArchScale是微软推出的一个神经架构预训练工具,支持多种前沿模型及扩展比例定律,提供优化器、高性能训练和全面评估方案等,适合专业研究和实验。
字节开源多语言翻译模型Seed-X,7B参数量,性能媲美甚至超越Gemini-2.5、Claude-3.5、GPT-4,在互联网等多领域表现优秀,支持28种语言。
京东团队开源了JoyAgent-JDGenie,一个端到端的多智能体系统,支持报告生成、代码解释、PPT制作和文件管理等任务。该系统准确率达到75.15%,包含多层次和多模式设计,并提供多种输出格式支持。
ConvertX 是一个支持超千种文件格式转换的开源项目,基于 TypeScript、Bun 和 Elysia 开发。它支持批量转换、密码保护和多账户系统等功能,并且可以本地部署或通过 Docker 部署。

Klee 是一款完全离线运行的开源本地AI桌面助手,支持Windows/macOS/Linux多平台使用。通过Ollama和LlamaIndex实现高效语义检索和知识管理,内置大模型引擎,保障数据安全。
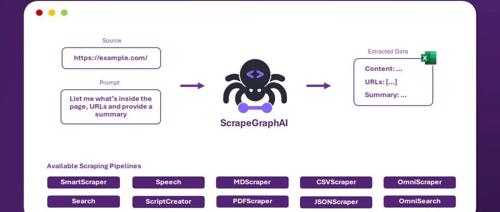
ScrapeGraphAI 是一个 Python 库用于快速创建网站和本地文档的爬取管道,只需提供提取信息提示。文章展示了三种使用该库的方法:SmartScraperGraph(单页)、SearchGraph(多页)和SpeechGraph(生成音频)。

本文介绍了五款AI工具及框架,包括Qwen Code、ShareGPT-4o-Image、Whisper App、OxyGent和any-llm。它们涵盖了代码工作流优化、图像生成数据集、音频转录应用以及智能体开发框架等多个领域。