
学术

推理能力飙升,指令遵循暴跌?MathIF基准揭示大模型“服从性漏洞”

研究揭示越擅长数学推理的模型反而更难完全遵守指令。这项发现强调了AI在处理复杂任务时的’聪明’与’听话’之间的权衡关系,未来有望构建既能深入思考又能严格守规矩的大模型。
ICML 2025 抛弃全量微调!北大提出VGP范式,语义低秩分解解锁ViG高效迁移

北京大学提出VGP方法,通过语义低秩分解增强图结构图像模型的参数高效迁移能力,在多种下游任务中实现媲美全量微调的性能。
导师放养,偷偷发了顶会……

万物皆卷的时代,越来越多的人通过高质量论文来增强竞争力。咕泡科技提供一站式科研辅导服务,包括选题、实验设计验证、创新点设计等环节,助力学生在短时间内提升学术能力,确保论文顺利发表。
自然语言+数值双反馈碾压传统RL!Critique-GRPO给模型“写批注”提效300%
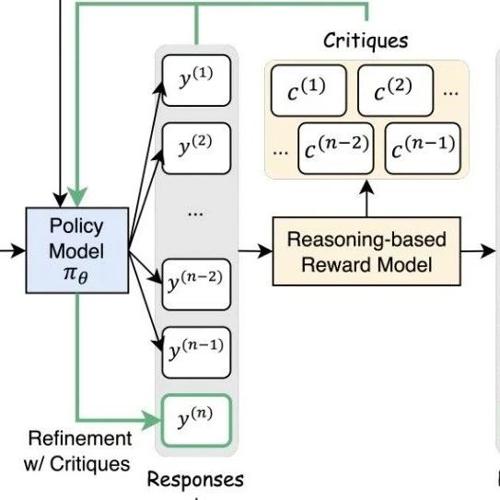
MLNLP社区是国内外知名的人工智能和技术交流平台,旨在促进机器学习和自然语言处理领域内的学术与产业界的交流合作。近日发布的论文探讨了改进语言模型推理能力的方法,并提出了一种名为Critique-GRPO的技术方案。

ICML 2025 全局池化+局部保留,CCA-Attention为LLM长文本建模带来突破性进展

的高效上下文建模。在 128K 超长序列上下文建模任务中,CCA-Attention 的推理速度是标

告别「失忆」AI!首个大模型记忆操作系统开源框架来了!

该项目由北京邮电大学白婷副教授指导,旨在解决大语言模型在长期对话中记忆断裂的问题。MemoryOS 是首个结合操作系统原理与人脑分层机制的大模型记忆管理系统,显著提升了AI的上下文连贯性和个性化记忆能力。
为什么用错奖励,模型也能提分?新研究:模型学的不是新知识,是思维

本文研究了语言模型对强化学习中奖励噪声的鲁棒性,即使翻转大部分奖励也能保持高下游任务表现。作者提出了思考模式奖励机制,并展示了其在数学和AI帮助性回复生成任务中的有效性。