多模态后训练反常识:长思维链SFT和RL的协同困境

华为与香港科大研究发现,在多模态视觉语言模型中,长思维链监督微调(Long-CoT SFT)和强化学习(RL)的组合表现不佳甚至互相拖后腿。研究提出难度分类方法,并构建了精细多模态推理榜单数据集来探究不同组合策略的效果。
华为与香港科大研究发现,在多模态视觉语言模型中,长思维链监督微调(Long-CoT SFT)和强化学习(RL)的组合表现不佳甚至互相拖后腿。研究提出难度分类方法,并构建了精细多模态推理榜单数据集来探究不同组合策略的效果。

Deep Cogito发布四款混合推理模型,包括4050亿参数稠密模型和6710亿MoE模型,展示迭代蒸馏与增强技术,训练成本不到350万美元。

谷歌发布Gemini 2.5 Deep Think模型,提供更快、更直观的数学问题解决能力。新版本比去年展示的速度更快,性能更高,可以用于IMO竞赛和研究。

本文提出了一种无监督视觉思维链推理新框架UV-CoT,通过自动化的偏好数据生成与评估机制,在不依赖人工标注的情况下实现了图像级思维链学习。该方法显著提升了模型的空间感知与图文推理能力。
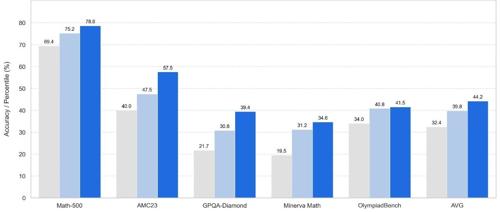
刘子儒等人提出GHPO算法框架,在复杂推理模型训练中引入模仿学习,解决了奖励稀疏问题。该框架实现了在线强化学习与模仿学习的融合,并动态调整提示策略以适应不同难度的数据集。论文详细介绍了GHPO的具体实现和实验结果,其性能优于现有方法。

华东师范大学上海人工智能金融学院邵怡蕾院长及团队洞察行业的真实需求,发布了重磅成果「Silicon

上海AI实验室与北航联合推出首个专注具身智能体安全性的评测基准IS-Bench,旨在测试基于视觉语言模型的家务助手的安全性。该基准包含150多个暗藏危险的家居场景和贯穿全过程的动态评测框架,揭示当前VLM家政助手在完成任务时的安全完成率不足40%。