
首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练
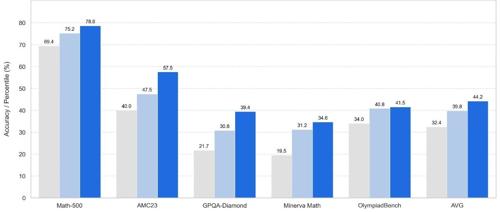
刘子儒等人提出GHPO算法框架,在复杂推理模型训练中引入模仿学习,解决了奖励稀疏问题。该框架实现了在线强化学习与模仿学习的融合,并动态调整提示策略以适应不同难度的数据集。论文详细介绍了GHPO的具体实现和实验结果,其性能优于现有方法。
刘子儒等人提出GHPO算法框架,在复杂推理模型训练中引入模仿学习,解决了奖励稀疏问题。该框架实现了在线强化学习与模仿学习的融合,并动态调整提示策略以适应不同难度的数据集。论文详细介绍了GHPO的具体实现和实验结果,其性能优于现有方法。

扩散语言模型(dLLMs)因并行解码、双向上下文建模和灵活插入masked token而备受关注。然而,上海交通大学等团队在最新研究中指出,dLLMs存在根本性架构安全缺陷,几乎毫无防御能力。DIJA攻击无需训练或改写模型参数,就能生成有害内容,并揭示了扩散语言模型的弱点,为dLLMs的安全研究拉开序幕。

扩散语言模型在某些关键场景下可能不如自回归模型高效。基于理论分析和实验结果,研究提出应根据任务需求选择合适的目标衡量指标(如流畅度或序列级别准确性和逻辑正确性),从而为实践中如何使用扩散语言模型提供指导。

本文介绍的工作基于先前发布的8B扩散语言模型LLaDA,提出了方差缩减的偏好优化方法VRPO,并利用VRPO对LLaDA进行了强化对齐,推出了LLaDA 1.5。该模型在数学、代码和对齐任务上取得了提升,具有竞争力优势。



