
首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练
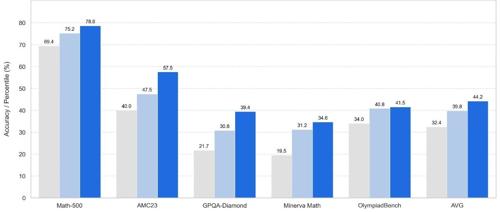
刘子儒等人提出GHPO算法框架,在复杂推理模型训练中引入模仿学习,解决了奖励稀疏问题。该框架实现了在线强化学习与模仿学习的融合,并动态调整提示策略以适应不同难度的数据集。论文详细介绍了GHPO的具体实现和实验结果,其性能优于现有方法。
刘子儒等人提出GHPO算法框架,在复杂推理模型训练中引入模仿学习,解决了奖励稀疏问题。该框架实现了在线强化学习与模仿学习的融合,并动态调整提示策略以适应不同难度的数据集。论文详细介绍了GHPO的具体实现和实验结果,其性能优于现有方法。
FVDM & Pusa 提出了一种新的视频扩散模型 (FVDM),通过引入向量化时间步变量 (VTV) 解决了传统视频生成的局限性。Pusa 项目利用非破坏性微调方法将预训练模型成本降低了数倍,展示了低成本、高灵活视频生成的新时代。