

0x0. 前言
传统大模型推理每次收到新请求都要从头计算 KV Cache ,除非当前请求和其它请求有公共前缀,则这部分前缀可以复用已经计算好的KV Cache,否则需要重新计算。尤其处理长文本(如 100 K token 文档)时 GPU 显存和计算资源消耗巨大。LMCache (https://github.com/LMCache/LMCache) 的核心突破是解耦了 KV Cache 的生成与使用,它的核心feature如下:
跨层级存储:将高频使用的 KV Cache 缓存在 GPU 显存→CPU 内存→本地磁盘三级存储中,显存不足时自动下沉跨请求复用:不只是相同前缀可复用(如传统 Prefix Caching),任意位置重复文本的 KV Cache 均可被提取重用分布式共享:多个 vLL 实例可共享同一缓存池,避免重复计算基于锁页内存+cuda kernel的zero-copy transfer:即在cuda kernel中直接访问锁页内存进行拷贝,cuda可以直接访问锁页内存,但无法直接访问普通cpu内存
在 32 K 上下文的多轮对话场景中,TTFT(首 Token 延迟)从 1.8 秒降至 0.4 秒,GPU 利用率下降 40%。
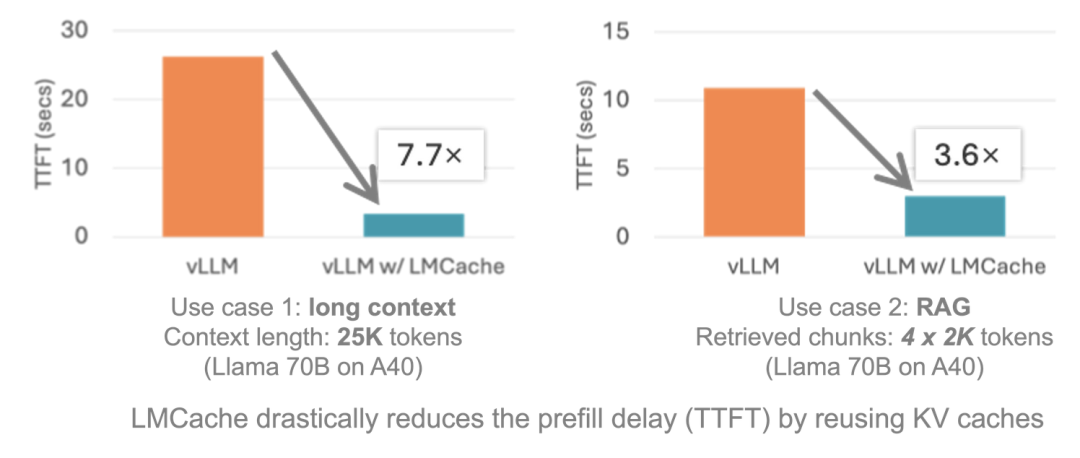
最近LMCache也支持了SGLang。虽然SGLang本身已经有HiCache这个拥有类似功能的组件了,LMCache对SGLang代码的修改部分也没有提交到SGLang仓库,但是了解这里的适配方式可以对LMCache的运行流程以及SGLang的KV Cache管理有更深入的理解。基于此,这篇博客将基于 https://github.com/LMCache/LMCache/pull/869 这个完整的端到端支持SGLang的PR 和 https://github.com/Oasis-Git/sglang/tree/lmcache/benchmark/benchmark_lmcache 这里对SGLang的改造来速览一下在LMCache中如何支持新的推理框架并让其拥有上面提到的跨层级存储、跨请求复用、分布式共享的feature。目前有个限制是LMCache适配的SGLang不支持Layer-by-Layer的KV Cache传输,而是把每一层的KV Cache concat到一个张量中进行传输。
0x1. LMCache + SGLang 使用方式
本示例展示如何使用 SGLang 与 LMCache 的集成。
安装
本项目依赖 SGLang 仓库中一个待处理的拉取请求。在该 PR 合并前,请使用特定分支的代码而非 SGLang 主分支。
git clone https://github.com/Oasis-Git/sglang/tree/lmcache
cd sglang
pip install --upgrade pip
pip install -e "python[all]"
服务端脚本
要启动带 LMCache 的 SGLang 服务端,请运行:
export LMCACHE_USE_EXPERIMENTAL=True
export LMCACHE_CONFIG_FILE=lmcache_config.yaml
python -m sglang.launch_server --model-path Qwen/Qwen2.5-14B-Instruct --port 30000 --tp 2 --page-size 32 --enable-lmcache-connector
如需运行基准测试,请参考 https://github.com/Oasis-Git/sglang/tree/lmcache/benchmark/benchmark_lmcache
然后lmcache_config.yaml文件内容如下:
# Basic configurations
chunk_size: 64
# CPU offloading configurations
local_cpu: true
max_local_cpu_size: 60.0
其中,max_local_cpu_size 用来控制本地最大的offload内存大小,单位为GB。注意这里的内存是锁页内存,LM Cache做KV Cache传输使用的就是基于锁页内存+cuda kernel的zero-copy transfer,即在kernel中直接访问锁页内存进行拷贝(cuda可以直接访问锁页内存,但无法直接访问普通cpu内存)。
下一节在解析传输的cuda kernel实现中有一个get_kernel_ptr函数,这个函数获取的CPU内存必须是锁页内存:
template <typename T, typename TENSOR_TYPE>
T* get_kernel_ptr(TENSOR_TYPE& tensor) {
// Get the kernel-accessible pointer of the given type T
// Returns NULL if the tensor is on CPU and non-pinned
torch::Device device = tensor.device();
if (device.is_cuda()) {
returnstatic_cast<T*>(tensor.data_ptr());
} elseif (device.is_cpu() && tensor.is_pinned()) {
T* ptr;
cudaHostGetDevicePointer((void**)&ptr,
static_cast<void*>(tensor.data_ptr()), 0);
return ptr;
} elseif (device.is_cpu()) {
// return NULL;
TORCH_CHECK(false, "Invalid device. Device must be cuda or pinned cpu.");
} else {
TORCH_CHECK(false, "Invalid device. Device must be cuda or pinned cpu.");
}
}
0x2. LMCache SGLangGPUConnector 实现
SGLangGPUConnector 是LMCache中用于管理SGLang在CPU和GPU内存之间的KV Cache数据传输的连接器,继承了LMCache的GPUConnectorInterface类。从下面的代码看,SGLangGPUConnector 管理多层transformer的key和value缓存,通过槽位映射处理前缀缓存和部分缓存场景,支持多GPU环境。其核心优势在于减少内存拷贝开销、支持异步传输和智能同步机制,显著提升了大语言模型推理时的性能和内存效率。
class SGLangGPUConnector(GPUConnectorInterface):
"""
SGLang GPU连接器,用于管理GPU KV Cache的数据传输
GPU KV Cache应该是一个张量列表,每个层一个张量,分别有独立的key和value指针。
具体来说,我们有:
- kvcaches: Tuple[List[Tensor], List[Tensor]]
- 第一个元素是key张量列表,每个层一个张量
- 第二个元素是value张量列表,每个层一个张量
- 每个张量形状: [page_buffer_size, head_num, head_size]
该连接器使用指针数组来高效访问,管理SGLang在CPU和GPU内存之间的KV Cache数据传输。
它将产生/消费具有KV_2LTD格式的内存对象。
"""
def __init__(
self, hidden_dim_size: int, num_layers: int, use_gpu: bool = False, **kwargs
):
"""
初始化SGLang GPU连接器
Args:
hidden_dim_size: 隐藏层维度大小
num_layers: 模型层数
use_gpu: 是否使用GPU缓冲区
**kwargs: 其他参数,包括chunk_size、device、dtype等
"""
self.hidden_dim_size = hidden_dim_size
self.num_layers = num_layers
# 在CPU上创建key和value指针数组,用于存储每层的张量指针
self.key_pointers = torch.empty(num_layers, dtype=torch.int64, device="cpu")
self.value_pointers = torch.empty(num_layers, dtype=torch.int64, device="cpu")
# 在GPU上存储key和value指针的字典,按设备索引组织
self.key_pointers_on_gpu: dict[int, torch.Tensor] = {}
self.value_pointers_on_gpu: dict[int, torch.Tensor] = {}
self.page_buffer_size = 0
# GPU缓冲区,用于临时存储数据
self.gpu_buffer: Optional[torch.Tensor] = None
if use_gpu:
# 使用GPU时必须提供chunk_size和device参数
assert"chunk_size"in kwargs, (
"chunk_size should be provided to create a GPU buffer."
)
assert"device"in kwargs, (
"device should be provided to create a GPU buffer."
)
# 根据chunk_size创建GPU缓冲区
shape = self.get_shape(kwargs["chunk_size"])
self.gpu_buffer = torch.empty(
shape, dtype=kwargs["dtype"], device=kwargs["device"]
)
logger.info(f"GPU buffer: {self.gpu_buffer.shape}")
def _initialize_pointers(self, kv_caches: List[torch.Tensor]) -> torch.Tensor:
"""
初始化指针数组,将CPU上的指针复制到GPU上
Args:
kv_caches: KV Cache列表,包含key和value张量
Returns:
GPU上的key和value指针数组
"""
k, v = kv_caches
# 将每层key和value张量的内存地址存储到CPU指针数组中
self.key_pointers.numpy()[:] = [t.data_ptr() for t in k]
self.value_pointers.numpy()[:] = [t.data_ptr() for t in v]
device = k[0].device
assert device.type == "cuda", "The device should be CUDA."
idx = device.index
# 如果该GPU设备还没有指针数组,则创建
if idx notin self.key_pointers_on_gpu:
self.key_pointers_on_gpu[idx] = torch.empty(
self.num_layers, dtype=torch.int64, device=device
)
if idx notin self.value_pointers_on_gpu:
self.value_pointers_on_gpu[idx] = torch.empty(
self.num_layers, dtype=torch.int64, device=device
)
# 将CPU指针复制到GPU上
self.key_pointers_on_gpu[idx].copy_(self.key_pointers)
self.value_pointers_on_gpu[idx].copy_(self.value_pointers)
# 记录页面缓冲区大小
self.page_buffer_size = k[0].shape[0]
return self.key_pointers_on_gpu[idx], self.value_pointers_on_gpu[idx]
@_lmcache_nvtx_annotate
def to_gpu(self, memory_obj: MemoryObj, start: int, end: int, **kwargs):
"""
将内存对象中的数据传输到GPU
期望kwargs中包含'kvcaches'参数,这是一个K和V张量的嵌套元组。
kvcaches应该对应"整个token序列"。
注意:
1. 此函数期望'slot_mapping'是一个"部分槽位映射",
其长度与未缓存的token序列相同。
2. 在有前缀缓存的情况下,slot_mapping将以-1开始直到匹配前缀结束。
start和end应该永远不会与前缀缓存重叠(这意味着底层CUDA kernel 永远不会在slot_mapping中看到-1)
Args:
memory_obj: 要传输的内存对象
start: 起始位置
end: 结束位置
**kwargs: 包含kvcaches和slot_mapping等参数
Raises:
ValueError: 如果没有提供'kvcaches'或'slot_mapping'
AssertionError: 如果内存对象没有张量
"""
assert memory_obj.tensor isnotNone
# 检查内存对象格式
if memory_obj.metadata.fmt != MemoryFormat.KV_2LTD:
raise ValueError(
"The memory object should be in KV_2LTD format in"
" order to be processed by VLLMPagedMemGPUConnector"
)
# 验证必需参数
if"kvcaches"notin kwargs:
raise ValueError("'kvcaches' should be provided in kwargs.")
if"slot_mapping"notin kwargs:
raise ValueError("'slot_mapping' should be provided in kwargs.")
offset = kwargs.get("offset", 0)
kvcaches: List[torch.Tensor] = kwargs["kvcaches"]
slot_mapping: torch.Tensor = kwargs["slot_mapping"]
# 初始化指针并执行数据传输
key_pointers, value_pointers = self._initialize_pointers(kvcaches)
lmc_ops.multi_layer_kv_transfer_unilateral(
memory_obj.tensor,
key_pointers,
value_pointers,
slot_mapping[start - offset : end - offset],
kvcaches[0][0].device,
self.page_buffer_size,
False, # False表示从CPU到GPU的传输
)
@_lmcache_nvtx_annotate
def from_gpu(self, memory_obj: MemoryObj, start: int, end: int, **kwargs):
"""
从GPU传输数据到内存对象
期望kwargs中包含'kvcaches'参数,这是一个K和V张量的嵌套元组。
kvcaches应该对应"整个token序列"。
会将memory_obj.metadata.fmt设置为MemoryFormat.KV_2LTD。
注意:
1. 此函数期望'slot_mapping'是一个"部分槽位映射",
其长度与未缓存的token序列相同。
2. 在有前缀缓存的情况下,slot_mapping将以-1开始直到匹配前缀结束。
start和end应该永远不会与前缀缓存重叠(这意味着底层CUDA kernel 永远不会在slot_mapping中看到-1)
Args:
memory_obj: 目标内存对象
start: 起始位置
end: 结束位置
**kwargs: 包含kvcaches和slot_mapping等参数
Raises:
ValueError: 如果没有提供'kvcaches'或'slot_mapping'
AssertionError: 如果内存对象没有张量
"""
assert memory_obj.tensor isnotNone
# 验证必需参数
if"kvcaches"notin kwargs:
raise ValueError("'kvcaches' should be provided in kwargs.")
if"slot_mapping"notin kwargs:
raise ValueError("'slot_mapping' should be provided in kwargs.")
kvcaches: List[torch.Tensor] = kwargs["kvcaches"]
slot_mapping: torch.Tensor = kwargs["slot_mapping"]
# 初始化指针
key_pointers, value_pointers = self._initialize_pointers(kvcaches)
# 根据是否有GPU缓冲区选择不同的传输策略
if self.gpu_buffer isNoneor end - start != self.gpu_buffer.shape[2]:
# 直接传输:GPU -> 内存对象
lmc_ops.multi_layer_kv_transfer_unilateral(
memory_obj.tensor,
key_pointers,
value_pointers,
slot_mapping[start:end],
kvcaches[0][0].device,
self.page_buffer_size,
True, # True表示从GPU到CPU的传输
)
else:
# 使用GPU缓冲区作为中间存储:kvcaches -> gpu_buffer -> memobj
assert self.gpu_buffer.device == kvcaches[0][0].device
tmp_gpu_buffer = self.gpu_buffer[:, :, : end - start, :]
lmc_ops.multi_layer_kv_transfer_unilateral(
tmp_gpu_buffer,
key_pointers,
value_pointers,
slot_mapping[start:end],
kvcaches[0][0].device,
self.page_buffer_size,
True,
)
# 将GPU缓冲区数据复制到内存对象
memory_obj.tensor.copy_(tmp_gpu_buffer, non_blocking=True)
# 如果目标缓冲区不是CUDA设备,强制同步
ifnot memory_obj.tensor.is_cuda:
# 注意:为了更好的性能,我们可能不想对每个内存对象都同步
torch.cuda.synchronize()
def get_shape(self, num_tokens: int) -> torch.Size:
"""
获取指定token数量的张量形状
Args:
num_tokens: token数量
Returns:
张量形状:[2, num_layers, num_tokens, hidden_dim_size]
"""
return torch.Size([2, self.num_layers, num_tokens, self.hidden_dim_size])
# TODO(Yuwei): need to optimize to enable real batching
def batched_from_gpu(self, memory_objs, starts, ends, **kwargs):
"""
批量从GPU传输数据到多个内存对象
注意:当前实现是串行的,需要优化以支持真正的批处理
Args:
memory_objs: 内存对象列表
starts: 起始位置列表
ends: 结束位置列表
**kwargs: 其他参数
"""
for memory_obj, start, end in zip(memory_objs, starts, ends, strict=False):
self.from_gpu(memory_obj, start, end, **kwargs)
注意这里的memory_obj对象的来源是:
kv_shape = self.gpu_connector.get_shape(num_tokens)
kv_dtype = self.metadata.kv_dtype
# TODO (Jiayi): should be batched in the future
memory_obj = self.storage_manager.allocate(kv_shape, kv_dtype)
上面的get_shape函数返回的形状是return torch.Size([2, self.num_layers, num_tokens, self.hidden_dim_size]),也可以说明这里对一个token计算完之后再整体传输的。
这个连接器里面的核心kernel是lmc_ops.multi_layer_kv_transfer_unilateral,下面解析一下这个kernel的实现。
/* 计算LMCache中KV Cache张量的线性偏移量
* k_or_v: 0表示key, 1表示value
* layer_idx: 层索引
* token_idx: token索引
* scalar_offset: 在单个token内的标量偏移
* scalars_per_token: 每个token包含的标量数量
* num_tokens: 总token数
* num_layers: 模型层数
*/
__device__ __forceinline__ int64_t
key_value_offset(const int k_or_v, const int layer_idx, const int token_idx,
const int scalar_offset, const int scalars_per_token,
const int num_tokens, const int num_layers) {
return k_or_v * num_layers * num_tokens * scalars_per_token +
layer_idx * num_tokens * scalars_per_token +
token_idx * scalars_per_token + scalar_offset;
}
/* 计算在分页缓冲区中的线性偏移量
* token_idx: token在序列中的索引
* scalar_offset: 在单个token内的标量偏移
* scalars_per_token: 每个token包含的标量数量
*/
__device__ __forceinline__ int64_t page_buffer_offset_unilateral(
const int token_idx, const int scalar_offset, const int scalars_per_token) {
return token_idx * scalars_per_token + scalar_offset; // 线性地址计算
}
/* 多层KV Cache传输 kernel 函数
* 模板参数:
* scalar_t: 数据类型模板
* DIRECTION: 传输方向(true:分页缓冲区->LMCache, false:LMCache->分页缓冲区)
* 参数说明:
* key_value: LMCache的KV Cache张量[2层, num_layers, num_tokens, scalars_per_token]
* key_ptrs/value_ptrs: 各层key/value的指针数组
* slot_mapping: token到分页缓冲区的槽位映射
* scalars_per_token: 每个token的标量元素数
* num_tokens: 总token数
* num_layers: 模型层数
* page_buffer_size: 分页缓冲区大小
*/
template <typenamescalar_t, bool DIRECTION>
__global__ void load_and_reshape_multi_layer_kernel_unilateral(
scalar_t* __restrict__ key_value, // LMCache的KV Cache张量
scalar_t** __restrict__ key_ptrs, // 各层key指针数组
scalar_t** __restrict__ value_ptrs, // 各层value指针数组
const int64_t* __restrict__ slot_mapping, // 槽位映射表
const int scalars_per_token, const int num_tokens, const int num_layers,
const int page_buffer_size) {
// 获取当前线程处理的维度信息
constint token_id = blockIdx.x; // 处理第几个token
constint layer_id = blockIdx.y; // 处理第几层
constint k_or_v = blockIdx.z; // 0:处理key, 1:处理value
constint tid = threadIdx.x; // 线程ID
constint num_threads = blockDim.x;// 总线程数
// 获取当前token对应的分页缓冲区槽位
constint64_t slot_idx = slot_mapping[token_id];
int64_t* key_ptr = key_ptrs[layer_id]; // 当前层的key指针
int64_t* value_ptr = value_ptrs[layer_id]; // 当前层的value指针
if (slot_idx < 0) { // 无效槽位直接返回
return;
}
// 并行拷贝数据: 每个线程处理token内的部分元素
for (int i = tid; i < scalars_per_token; i += num_threads) {
// 计算LMCache中的目标偏移
constint64_t lmcache_offset = key_value_offset(
k_or_v, layer_id, token_id, i, scalars_per_token, num_tokens, num_layers);
// 计算分页缓冲区中的源偏移
constint64_t sgl_offset = page_buffer_offset_unilateral(
slot_idx, i, scalars_per_token);
// 根据处理类型(key/value)和方向进行数据拷贝
if (k_or_v == 0) { // 处理key
if (DIRECTION) // 分页缓冲区 -> LMCache
key_value[lmcache_offset] = key_ptr[sgl_offset];
else // LMCache -> 分页缓冲区
key_ptr[sgl_offset] = key_value[lmcache_offset];
} else { // 处理value
if (DIRECTION) // 分页缓冲区 -> LMCache
key_value[lmcache_offset] = value_ptr[sgl_offset];
else // LMCache -> 分页缓冲区
value_ptr[sgl_offset] = key_value[lmcache_offset];
}
}
}
/* 多层KV Cache传输入口函数
* 参数说明:
* key_value: 目标缓存张量[2, num_layers, num_tokens, elements]
* key_ptrs/value_ptrs: 各层key/value指针的Tensor
* slot_mapping: 槽位映射Tensor[num_tokens]
* paged_memory_device: 分页内存所在设备
* page_buffer_size: 分页缓冲区大小
* direction: 传输方向(true:分页缓冲区->LMCache)
*/
void multi_layer_kv_transfer_unilateral(
torch::Tensor& key_value, // 目标缓存张量
const torch::Tensor& key_ptrs, // key指针数组
const torch::Tensor& value_ptrs, // value指针数组
const torch::Tensor& slot_mapping, // 槽位映射
const torch::Device& paged_memory_device, // 分页内存设备
const int page_buffer_size, // 分页缓冲区大小
const bool direction) { // 传输方向
// 获取各Tensor的底层指针
int64_t* key_value_ptr = get_kernel_ptr<int64_t, torch::Tensor>(key_value);
int64_t** key_ptrs_ptr = get_kernel_ptr<int64_t*, const torch::Tensor>(key_ptrs);
int64_t** value_ptrs_ptr = get_kernel_ptr<int64_t*, const torch::Tensor>(value_ptrs);
constint64_t* slot_mapping_ptr = get_kernel_ptr<constint64_t, const torch::Tensor>(slot_mapping);
// 计算 kernel 参数
int num_layers = key_value.size(1); // 模型层数
int num_tokens = slot_mapping.size(0); // token总数
int num_origin_elements = key_value.size(3); // 每个token元素数
int elements_per_qword = 8 / key_value.element_size(); // 每个qword包含元素数
int num_qwords = num_origin_elements / elements_per_qword; // 需要处理的qword数
int k_or_v_size = 2; // 同时处理key和value
// 设置CUDA kernel 执行配置
dim3 grid(key_value.size(2), key_value.size(1), k_or_v_size); // 三维网格
dim3 block(std::min(num_qwords, 128)); // 每个块最多128个线程
// 设置设备上下文和CUDA流
const at::cuda::OptionalCUDAGuard device_guard(paged_memory_device);
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
// 根据传输方向选择 kernel 模板
if (not direction) { // LMCache -> 分页缓冲区
lmc::load_and_reshape_multi_layer_kernel_unilateral<int64_t, false>
<<<grid, block, 0, stream>>>(
key_value_ptr, key_ptrs_ptr, value_ptrs_ptr, slot_mapping_ptr,
num_qwords, num_tokens, num_layers, page_buffer_size);
C10_CUDA_KERNEL_LAUNCH_CHECK(); // 检查 kernel 启动状态
} else { // 分页缓冲区 -> LMCache
lmc::load_and_reshape_multi_layer_kernel_unilateral<int64_t, true>
<<<grid, block, 0, stream>>>(
key_value_ptr, key_ptrs_ptr, value_ptrs_ptr, slot_mapping_ptr,
num_qwords, num_tokens, num_layers, page_buffer_size);
C10_CUDA_KERNEL_LAUNCH_CHECK();
}
}
void multi_layer_kv_transfer_unilateral(
torch::Tensor& key_value, const torch::Tensor& key_ptrs,
const torch::Tensor& value_ptrs, const torch::Tensor& slot_mapping,
const torch::Device& paged_memory_device, const int page_buffer_size,
const bool direction);
0x3. SGLangGPUConnector的封装
有了这个SGLangGPUConnector连接器之后,还需要在 https://github.com/LMCache/LMCache/blob/dev/lmcache/integration/sglang/sglang_adapter.py 里面封装一个更高一级的LMCacheConnector类,这个类有2个核心的api:
-
load_kv:从LMCache缓存中检索已存储的KV Cache并加载到SGLang的GPU内存槽位中,支持跳过前缀token的加载 -
store_kv:将SGLang计算得到的KV Cache存储到LMCache缓存中,以便后续请求复用
并且这个类还托管了一些其它的关键信息,比如模型配置信息,分布式相关的rank,world_size,以及KV Cache池的引用等。
此外,我们还需要通过init_lmcache_engine函数创建LMCache缓存引擎,配置KV Cache的形状参数(层数、头数、头维度等),并创建SGLangGPUConnector实例来处理GPU内存与缓存之间的数据传输。
# Standard
from typing import List, Optional
# Third Party
from sglang.srt.configs.model_config import ModelConfig
import torch
# First Party
from lmcache.config import LMCacheEngineMetadata
from lmcache.integration.sglang.utils import ENGINE_NAME, lmcache_get_config
from lmcache.logging import init_logger
from lmcache.v1.cache_engine import LMCacheEngine, LMCacheEngineBuilder
from lmcache.v1.config import LMCacheEngineConfig
from lmcache.v1.gpu_connector import (
SGLangGPUConnector,
)
logger = init_logger(__name__)
def get_kv_cache_torch_dtype(dtype: str) -> torch.dtype:
"""获取KV Cache使用的torch数据类型(当前仅支持bfloat16)"""
# TODO: add support for other dtypes
return torch.bfloat16
def need_gpu_interm_buffer(lmcache_config: LMCacheEngineConfig):
"""判断是否需要GPU中间缓冲区(当NIXL优化未启用时需要)"""
if lmcache_config.enable_nixl:
returnFalse# NIXL优化启用时直接传输,无需中间缓冲区
else:
returnTrue # 默认需要中间缓冲区
def init_lmcache_engine(
model_config: ModelConfig,
tp_size: int,
rank: int,
world_size: int,
) -> Optional[LMCacheEngine]:
"""
初始化LMCache引擎
Args:
model_config: 模型配置信息
tp_size: 张量并行度
rank: 当前进程的GPU排名
world_size: 总GPU数量
Returns:
LMCacheEngine实例(如果已存在则返回None)
"""
# 检查是否已存在引擎实例
if LMCacheEngineBuilder.get(ENGINE_NAME) isnotNone:
returnNone
# 获取LMCache配置
config = lmcache_get_config()
assert isinstance(config, LMCacheEngineConfig), "需要LMCache v1配置参数"
# 构建KV Cache形状参数(用于内存池分配)
kv_dtype = get_kv_cache_torch_dtype(model_config.dtype)
num_layer = model_config.num_hidden_layers # 模型层数
chunk_size = config.chunk_size # 缓存块大小
num_kv_head = model_config.get_num_kv_heads(tp_size) # KV头数
head_dim = model_config.head_dim # 注意力头维度
kv_shape = (num_layer, 2, chunk_size, num_kv_head, head_dim) # 形状: [层数, K/V, 块大小, 头数, 头维度]
# 设置当前CUDA设备
torch.cuda.device(rank)
device = torch.device(f"cuda:{rank}")
# 构建引擎元数据
metadata = LMCacheEngineMetadata(
model_config.model_path, # 模型路径
world_size, # 总GPU数
rank, # 当前GPU排名
"sgl", # 后端标识(sglang)
kv_dtype, # KV数据类型
kv_shape, # KV Cache形状
)
# 创建GPU连接器
use_gpu = need_gpu_interm_buffer(config)
hidden_dim_size = num_kv_head * head_dim # 隐藏层维度 = 头数 * 头维度
if config.use_layerwise:
raise ValueError("暂不支持分层连接器")
else:
# 创建SGLang GPU连接器实例
sglang_gpu_connector = SGLangGPUConnector(
hidden_dim_size,
num_layer,
use_gpu=use_gpu,
chunk_size=chunk_size,
dtype=kv_dtype,
device=device,
)
# 创建/获取缓存引擎实例
engine = LMCacheEngineBuilder.get_or_create(
ENGINE_NAME, config, metadata, sglang_gpu_connector
)
return engine
class LMCacheConnector:
"""LMCache与SGLang的对接类,管理KV Cache的加载/存储"""
def __init__(
self,
sgl_config: ModelConfig,
tp_size: int,
rank: int,
world_size: int,
k_pool: List[torch.Tensor], # Key缓存池
v_pool: List[torch.Tensor], # Value缓存池
):
"""初始化连接器,创建LMCache引擎实例"""
self.lmcache_engine = init_lmcache_engine(
sgl_config,
tp_size,
rank,
world_size,
)
# 保存配置信息
self.sgl_config = sgl_config
self.tp_size = tp_size # 张量并行度
self.rank = rank # 当前GPU排名
self.world_size = world_size # 总GPU数
self.k_pool = k_pool # Key缓存池引用
self.v_pool = v_pool # Value缓存池引用
####################
# Worker side APIs
####################
def load_kv(
self, token_ids: torch.Tensor, slot_mapping: torch.Tensor, offset: int = 0
) -> None:
"""从缓存加载KV到指定槽位
Args:
token_ids: 输入token ID序列
slot_mapping: token到缓存槽位的映射
offset: 需要跳过的起始token数
Returns:
实际加载的token数量
"""
# 参数校验
assert isinstance(token_ids, torch.Tensor)
assert isinstance(slot_mapping, torch.Tensor)
assert (len(token_ids) - offset) == len(slot_mapping)
# 将槽位映射转移到GPU
slot_mapping = slot_mapping.cuda()
# 创建加载掩码(跳过offset之前的token)
load_mask = torch.ones_like(token_ids, dtype=torch.bool)
load_mask[:offset] = False
# 调用引擎的检索接口
ret_token_mask = self.lmcache_engine.retrieve(
token_ids,
mask=load_mask,
kvcaches=[self.k_pool, self.v_pool], # 传入KV Cache池
slot_mapping=slot_mapping,
offset=offset,
)
return ret_token_mask.sum().item() # 返回实际加载的token数
def store_kv(
self, token_ids: torch.Tensor, slot_mapping: torch.Tensor, offset: int = 0
) -> None:
"""将KV存储到缓存指定槽位
Args:
token_ids: 输入token ID序列
slot_mapping: token到缓存槽位的映射
offset: 需要跳过的起始token数
"""
# 参数校验
assert isinstance(token_ids, torch.Tensor)
assert isinstance(slot_mapping, torch.Tensor)
assert len(token_ids) == len(slot_mapping)
# 将槽位映射转移到GPU
slot_mapping = slot_mapping.cuda()
# 创建全True存储掩码
store_mask = torch.ones_like(token_ids, dtype=torch.bool)
# 调用引擎的存储接口
self.lmcache_engine.store(
token_ids,
mask=store_mask,
kvcaches=[self.k_pool, self.v_pool], # 传入KV Cache池
slot_mapping=slot_mapping,
offset=offset,
)
def chunk_size(self):
"""获取当前配置的缓存块大小"""
return self.lmcache_engine.config.chunk_size
def reset(self):
"""重置缓存引擎"""
self.lmcache_engine.clear()
def close(self):
"""关闭缓存引擎"""
self.lmcache_engine.close()
感觉这里的命名叫做SGLangLMCacheConnector更合适?
0x4. 在SGLang中使用封装好的LMCacheConnector
SGLang在RadixCache的实现中完成和LMCacheConnector的对接。代码位置如下:
https://github.com/Oasis-Git/sglang/blob/lmcache/python/sglang/srt/mem_cache/radix_cache.py#L102-L461
关于RadixCache以及SGLang KV Cache的代码解析可以看:https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/kvcache-code-walk-through/readme-CN.md ,建议先阅读这个文档。
136-147行完成初始化
if self.token_to_kv_pool_allocator isnotNoneand enable_lmcache_connector:
self.lmcache_connector = LMCacheConnector(
sgl_config=model_config,
tp_size=tp_size,
rank=rank,
world_size=world_size,
k_pool=self.token_to_kv_pool_allocator._kvcache.k_buffer,
v_pool=self.token_to_kv_pool_allocator._kvcache.v_buffer,
)
# 创建异步写入队列和线程
self.writer_queue = queue.Queue()
self.shutdown_event = threading.Event()
self.writer_thread = threading.Thread(target=self._lmcache_writer_worker)
self.writer_thread.start()
-
创建 LMCacheConnector 实例,连接到底层的 KV 缓存池 -
启动独立的写入线程,避免阻塞主线程 -
传递 GPU 内存池的引用给 LMCache
match_prefix 中的核心逻辑(第 187-254 行)
-
前置检查和准备
if self.lmcache_connector_enabled():
# 检查前缀是否页对齐
if len(value) % self.page_size != 0:
raise ValueError("The prefix is not page-aligned")
uncached_paged_aligned_len = len(key) - len(value)
chunk_size = self.lmcache_connector.chunk_size()
-
处理完全命中的情况,如果 RadixCache 已经包含了所有需要的 tokens,直接返回。
if uncached_paged_aligned_len == 0:
return MatchResult(
device_indices=value,
last_device_node=last_node,
last_host_node=last_node,
)
-
计算前缀padding,因为LMCache 使用 chunk 对齐,需要计算填充长度。
if len(value) % chunk_size != 0:
prefix_padding_len = len(value) % chunk_size
else:
prefix_padding_len = 0
-
构造槽位映射,前缀填充部分用 -1 标记(表示不需要存储),后面是实际分配的内存索引
slot_mapping = torch.cat([
torch.tensor([-1] * prefix_padding_len, dtype=torch.int64, device=self.device),
token_prealloc_indices.detach().clone().to(torch.int64).to(self.device)
])
-
从LMCache加载数据,
num_retrieved_tokens = self.lmcache_connector.load_kv(
key_tokens,
slot_mapping,
offset=len(value) - prefix_padding_len,
)
-
处理加载结果
if num_retrieved_tokens > 0:
# 释放未使用的内存
self.token_to_kv_pool_allocator.free(
token_prealloc_indices[(num_retrieved_tokens - prefix_padding_len):]
)
# 创建新的树节点
new_node = TreeNode()
new_node.key = key[len(value):len(value) + (num_retrieved_tokens - prefix_padding_len)]
new_node.value = token_prealloc_indices[:num_retrieved_tokens - prefix_padding_len]
new_node.parent = last_node
last_node.children[self.get_child_key_fn(...)] = new_node
# 更新缓存状态
last_node = new_node
value = torch.cat([value, token_prealloc_indices[:num_retrieved_tokens - prefix_padding_len]])
self.evictable_size_ += (num_retrieved_tokens - prefix_padding_len)
else:
# 没有检索到数据,释放所有预分配的内存
self.token_to_kv_pool_allocator.free(token_prealloc_indices)
异步存储逻辑(第 311-319 行)
在 cache_finished_req 方法中:
if self.lmcache_connector_enabled():
kv_indices_storage, last_node, _, _ = self.match_prefix(token_ids[:page_aligned_len])
if len(kv_indices_storage) != len(token_ids[:page_aligned_len]):
raise ValueError("The KV cache is not page-aligned")
self.inc_lock_ref(last_node) # 增加引用计数,防止被驱逐
self.writer_queue.put((token_ids[:page_aligned_len], kv_indices_storage, last_node))
异步写入线程(第 420-444 行)
def _lmcache_writer_worker(self):
whilenot self.shutdown_event.is_set():
try:
item = self.writer_queue.get(timeout=1)
if item isNone:
break
token_ids, kv_indices_to_store, last_node = item
try:
self.lmcache_connector.store_kv(
torch.tensor(token_ids, device=self.device),
kv_indices_to_store.detach().clone().to(torch.int64).to(self.device),
)
finally:
self.dec_lock_ref(last_node) # 释放引用计数
self.writer_queue.task_done()
except queue.Empty:
continue
except Exception as e:
logger.error(f"Error in LMCache writer thread: {e}", exc_info=True)
0x5. 总结
LMCache通过解耦KV Cache的生成与使用,实现了跨层级存储、跨请求复用和分布式共享等核心功能。其与SGLang的集成主要通过SGLangGPUConnector连接器实现,该连接器利用基于锁页内存的zero-copy传输技术,通过CUDA kernel高效地在GPU显存与CPU内存间传输多层KV Cache数据。在SGLang的RadixCache中,通过LMCacheConnector封装类提供load_kv和store_kv接口,结合异步写入机制,可以显著提升了长文本/RAG等场景推理的性能。
(文:GiantPandaCV)