7B智能体仅凭9个任务训练即超越R1!上交大打造AI-for-AI新范式

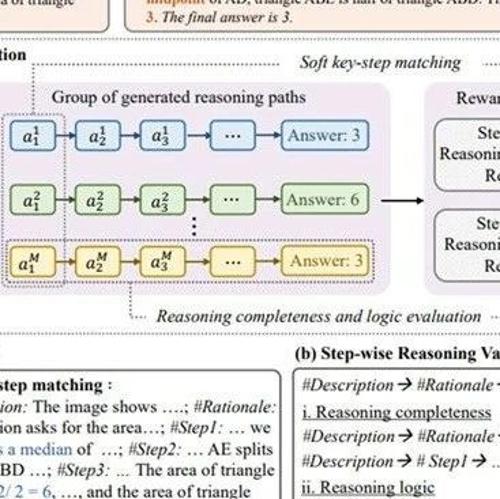
研究提出了一种新的训练框架,让大模型自主设计和优化AI算法,显著减少人类干预。通过经验学习范式,7B参数的大模型ML-Agent在9个任务上持续探索学习,最终超越了671B规模的智能体。
研究提出了一种新的训练框架,让大模型自主设计和优化AI算法,显著减少人类干预。通过经验学习范式,7B参数的大模型ML-Agent在9个任务上持续探索学习,最终超越了671B规模的智能体。

苹果公司高管已就可能竞购知名 AI 初创公司 Perplexity 举行了内部会谈,Perplexity 团队和技术对苹果具有吸引力。
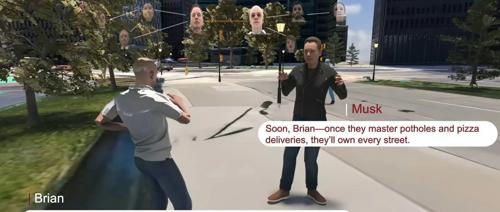
虚拟社区通过结合真实地理空间数据与生成模型,创建了一个具有社会根基的交互式、可扩展开放世界场景,支持人类和机器人的社交及物理互动。

论文提出UniGRF统一生成式推荐框架,将召回和排序整合到一个自回归生成模型中,通过Ranking-Driven Enhancer和Gradient-Guided Adaptive Weighter实现高效协作与优化。实验表明其在多个公开数据集上性能显著优于现有SOTA模型。