


在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘。然而,传统的推荐系统普遍采用多阶段范式(如召回、排序),这种设计虽然在工程上实现了效率,却常常面临阶段间信息损失、性能瓶颈等问题。近年来,生成式人工智能的浪潮席卷全球,其强大的序列建模和内容生成能力为解决推荐系统的固有难题带来了新的曙光。如果能将推荐过程中的多个阶段融为一体,是否就能克服信息损失,实现更高效、更精准的推荐呢?
来自中国科学技术大学和华为诺亚方舟实验室的研究者们,在即将于 SIGIR 2025 会议上进行口头报告(Oral Presentation)的论文 Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model 中,给出了一份创新的答案。他们提出了一个名为 UniGRF 的统一生成式推荐框架,巧妙地实现了 “一石二鸟”,用单个生成模型同时处理推荐系统中的召回和排序两大核心任务。

-
论文标题:Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model
-
论文链接:
https://arxiv.org/abs/2504.16454
一、传统推荐范式的 “痛点” 与生成式 AI 的 “良方”
在工业界广泛应用的推荐系统中,通常首先通过召回阶段从海量物品库中快速筛选出一个较小的候选集,然后由排序阶段对这些候选物品进行精准打分和排序,最终呈现给用户。这种分而治之的多阶段级联模式保证了效率,但每个阶段独立训练和优化,上一阶段的丰富信息难以完整传递给下一阶段,信息茧房外的潜在兴趣点被过早过滤,造成了信息损失、偏差累积、阶段间难协作等固有问题。
受大语言模型(LLMs)在多任务处理上取得巨大成功的启发,UniGRF 创新性地将召回和排序整合到一个生成模型中,实现了信息的充分共享,同时保持了模型的通用性和可扩展性。
二、突破传统:如何用一个模型 “杀死两只鸟”?
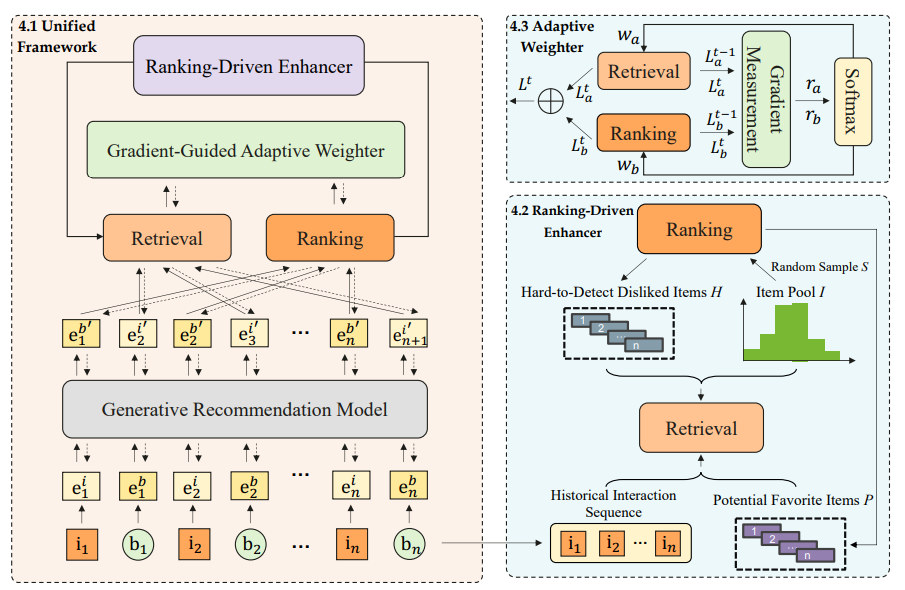
UniGRF 的核心思想是将检索和排序两个阶段的任务都统一转化为序列生成任务,并整合到同一个自回归生成模型中。具体来说,模型通过学习用户历史交互序列(物品 ID 序列、行为类型序列等),在生成输出序列时,特定位置的输出分别对应召回任务(预测下一个交互物品)和排序任务(预测当前物品的点击概率)。
这种统一框架带来了诸多优势:
1. 充分信息共享:由于参数在单一模型内共享,检索和排序任务可以充分利用彼此的信息,有效减少信息损失。
2. 模型无关性与即插即用:UniGRF 是一个灵活的框架,可以与各种主流的自回归生成模型架构(如 HSTU、Llama 等)无缝集成。
3. 潜在的效率提升:相比于维护两个独立的模型,单一模型在训练和推理上可能更具效率优势。
三、UniGRF 的两大 “秘密武器”
仅仅将两个任务放在一个模型里还不够,如何让它们高效协作并同步优化,是 UniGRF 成功的关键。为此,研究者设计了两大核心模块:
1. 排序驱动的增强器 (Ranking-Driven Enhancer):
这个模块旨在促进召回和排序两个阶段之间的高效协作。一般来说,排序阶段通常能更精准地捕捉用户细粒度的偏好。该增强器巧妙地利用排序阶段的高精度输出来指导和优化召回阶段。
-
难样本挖掘:识别那些在召回阶段被高估但两个阶段存在分歧的样本,将它们作为更具挑战性的负样本反馈给模型,提升模型的辨别能力。
-
潜在正样本识别:识别那些在负采样中被错误标记,但排序模型认为用户可能喜欢的样本,纠正其标签,为模型提供更准确的训练信号。
通过这种方式,形成了一个互相促进的增强闭环,并且这一切几乎不增加额外的计算开销。
2. 梯度引导的自适应加权器 (Gradient-Guided Adaptive Weighter):
在统一框架下,召回和排序两个任务的损失函数、收敛速度可能存在显著差异。如果简单地将两者损失相加,可能会导致模型在优化过程中厚此薄彼。该加权器通过实时监测两个任务梯度的变化率(即学习速度),动态地调整它们在总损失函数中的权重。如果一个任务学习较慢,就适当增加其权重,反之亦然。这确保了两个任务能够以协同的步伐前进,实现同步优化,最终达到整体性能的最优。
四、实验效果:显著超越 SOTA,验证统一框架威力
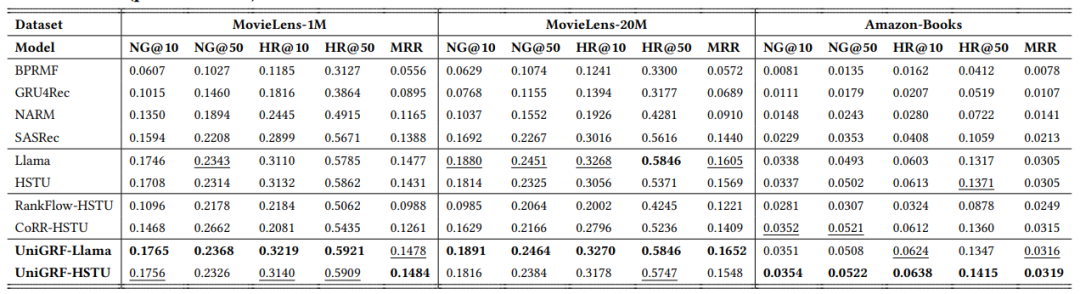
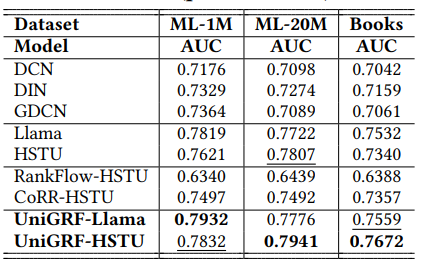
为了验证 UniGRF 的有效性,研究团队在三个公开的大型推荐数据集(MovieLens-1M, MovieLens-20M, Amazon-Books)上进行了大量实验。结果表明:
-
全面领先:无论是以 HSTU 还是 Llama 作为基础生成模型,UniGRF 在召回和排序两个任务上的性能均显著优于现有的 SOTA 基线模型,包括那些为单一任务设计的强大生成模型以及传统的级联框架。
-
排序性能提升尤为显著:实验发现,UniGRF 对排序阶段的性能提升更为明显。这对于实际应用更为重要,因为排序结果直接决定了最终呈现给用户的推荐质量。
-
良好的可扩展性:实验还初步验证了 UniGRF 在模型参数扩展时的性能提升潜力,符合 “越大越好” 的缩放定律(Scaling Law)。
值得一提的是,传统的级联框架在适配生成式模型时表现不佳,甚至可能产生负面效果,这反过来凸显了 UniGRF 这种原生统一框架的优越性。
五、总结与展望
UniGRF 的提出,为生成式推荐系统领域贡献了一个新颖且高效的解决方案。它首次探索了在单一生成模型内统一召回与排序任务的可行性与巨大潜力,通过精心设计的协作与优化机制,有效克服了传统多阶段范式的信息损失问题。
这项工作不仅为学术界提供了新的研究视角,也为工业界构建更强大、更高效的推荐系统提供了有益的借鉴。未来,研究者们计划将该框架扩展到更多的推荐阶段(如预排序、重排),并在真实的工业场景中验证其大规模应用的可行性。
©
(文:机器之心)