


本文第一作者为张桂彬,新加坡国立大学25Fall计算机科学博士生;本文在南洋理工大学的王琨博士、上海人工智能实验室的白磊老师、和中国科学技术大学的王翔教授指导下完成。
LLM 智能体的时代,单个 Agent 的能力已到瓶颈,组建像 “智能体天团” 一样的多智能体系统已经见证了广泛的成功。但 “天团” 不是人越多越好,手动设计既费力又不讨好,现有的智能体自动化方法又只会 “一招鲜”,拿一套复杂阵容应对所有问题,导致 “杀鸡用牛刀”,成本高昂。
现在,一篇来自新加坡国立大学、上海 AI Lab、同济大学等机构并被 ICML 2025 接收为 Oral Presentation 的论文,为我们带来了全新的解题思路。
他们将神经网络架构搜索(NAS)的超网络(Supernet)思想引入 Agent 领域,首创了一个名为 “智能体超网”(Agentic Supernet)的概念。它不再寻找一个固定的最佳 “阵容”,而是根据任务难度,动态 “剪” 出一个量身定制的智能体团队。结果有多惊艳?性能超越现有方法最高 11.82%,推理成本却只有它们的 45%!

-
论文地址:https://arxiv.org/abs/2502.04180
-
Github 链接:https://github.com/bingreeky/MaAS
-
论文标题:Multi-agent Architecture Search via Agentic Supernet
智能体的 “一体化” 困境:
从设计内卷到资源浪费
如今,从 AutoGen 到 MetaGPT,各种多智能体系统(Multi-agent Systems)层出不穷,通过定制化的协作,其能力在多个领域(如代码生成,复杂通用 AI 任务)已超越了单个智能体。但一个核心痛点始终存在:这些系统的设计往往依赖于繁琐的人工配置和 Prompt 工程。 为了解决这个问题,研究界转向自动化设计,比如通过强化学习、进化算法、蒙特卡洛树搜索等方式寻找最优的 Agent 工作流。
然而,这又带来了新的困境:
1. 资源浪费 (Dilemma 1):诸如 AFlow 和 ADAS 这样的自动化多智能体系统优化方法倾向于找到一个极其复杂的 “万金油” 式系统,以确保在所有任务上表现优异。 但面对 “10+1*2.5=?” 这样的简单问题,动用一个需要数十次 LLM 调用的复杂系统,无疑是巨大的资源浪费。
2. 任务冲突 (Dilemma 2):在 GAIA 这样的多领域基准测试中,一个擅长文献总结的多智能体系统,不一定擅长网页浏览总结 —— 似乎不存在一个能在所有任务上都最优的 “全能冠军”。
面对这种 “要么手动内卷,要么自动浪费” 的局面,我们是否该换个思路了?
Agentic Supernet:
从 “选一个” 到 “按需生万物”
这篇论文的核心贡献,就是一次漂亮的 “范式转移” (Paradigm Reformulation)。作者提出,我们不应该再执着于寻找一个单一、静态的最优智能体架构。相反,我们应该去优化一个 “智能体超网”(Agentic Supernet) —— 这是一个包含海量潜在智能体架构的概率分布。

图 1 智能体超网络
这个 “超网” 就像一个巨大的 “能力兵工厂”,里面包含了诸如思维链(CoT)、工具调用(ReAct)、多智能体辩论(Debate)等各式各样的基础能力 “算子”(Agentic Operator)。当一个新任务(Query)到来时,一个 “智能控制器”(Controller)会快速分析任务的难度和类型,然后从这个 “兵工厂” 中,动态地、即时地挑选并组合最合适的几个 “算子”,形成一个量身定制的、不多不少、资源分配额刚刚好的临时智能体系统去解决问题。
上图生动地展示了这一点:
-
对于简单问题 (a, b):MaAS 在第二层就选择了 “提前退出”(Early-exit),用最简单的 I/O 或 ReAct 组合快速给出答案,极大节省了资源。
-
对于中等和困难问题 (c, d):MaAS 则会构建更深、更复杂的网络,调用更多的算子来确保问题得到解决。
这种 “按需分配、动态组合” 的哲学,正是大名鼎鼎的 NAS 的核心思想。如今,MaAS 框架将其成功地应用在了多智能体架构搜索(Multi-agent Architecture Search)上,可以说是 NAS 在 Agentic 时代的重生和胜利。
MaAS 的 “三板斧” 如何玩转智能体架构?
接下来,我们就一起拆解 MaAS 的 “独门秘籍”。其核心思想,可以概括为定义蓝图 → 智能调度 → 自我进化三步走战略。
第一板斧:定义万能 “蓝图” – Agentic Supernet
传统方法是设计一个具体的 Agent 架构 (System),而 MaAS 的第一步,就是定义一个包含所有可能性的 “宇宙”—— 智能体超网 (Agentic Supernet)。
1. 智能体算子 (Agentic Operator):首先,MaAS 将智能体系统拆解为一系列可复用的 “原子能力” 或 “技能模块”,也就是智能体算子 (O)。这包括了:
-
I/O: 最简单的输入输出。
-
CoT (Chain-of-Thought): 引导模型进行循序渐进的思考。
-
ReAct: 结合思考与工具调用。
-
Debate: 多个 Agent 进行辩论,优胜劣汰。
-
Self-Refine: 自我批判与修正。
-
… 等等,这个 “技能库” 是完全可以自定义扩展的!
2. 概率化智能体超网 (Probabilistic Agentic Supernet):有了这些智能体算子,MaAS 将它们组织成一个多层的、概率化的结构。你可以想象成一个分了好几层的巨大 “技能池”。
-
每一层都包含了所有可选的智能体算子。
-
每个模块在每一层被 “选中” 的概率(π)是不固定的,是可以学习和优化的。
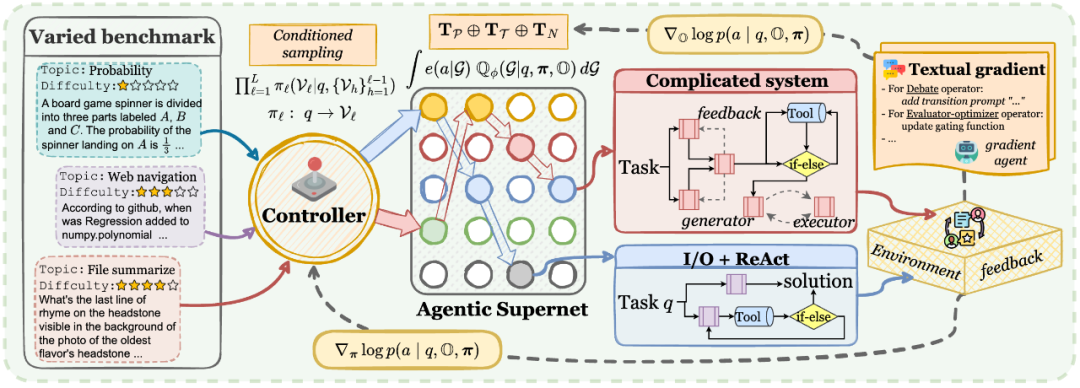
图 2 MaAS 自进化框架示意图
如图 2 所示的智能体超网,就是 MaAS 施展魔法的舞台。它不是一个静态的系统,而是一个智能体系统架构的概率分布空间。
第二板斧:智能 “调度师” – 按需采样架构
有了 “蓝图”,当一个具体的任务(Query q)来了,如何快速生成一个 “定制团队” 呢?这就轮到 MaAS 的 “智能调度师”—— 控制器网络 (Controller) 上场了。控制器的工作流程如下所示:
1. “阅读” 任务:控制器首先将输入的 Query q 进行编码,理解其意图和难度。
2. 逐层挑选:然后,它从超网的第一层开始,逐层为当前任务挑选最合适的 “技能模块”。
3. MoE 式动态选择:这里的挑选机制非常精妙,它采用了一种类似混合专家(MoE)的策略。
在每一层,控制器会为所有待选的技能模块计算一个 “激活分数”。这个分数取决于当前任务 q 以及之前层已经选定了哪些模块。
然后,它会从分数最高的模块开始,依次激活,直到这些被激活模块的累计分数总和超过一个预设的阈值 (thres)。
这个设计恰恰与 MaAS 的动态性紧密相关!这意味着:
-
简单任务可能在某一层只激活一个智能体算子就够了。
-
复杂任务则会激活更多的算子,可能是两个、甚至三个,以保证足够的解决能力。
-
同时,如果 “早停 (Early-Exit)” 这个特殊的算子被选中,整个采样过程就会提前结束,完美实现了 “见好就收”。
通过这种方式,MaAS 为每一个 Query 都动态生成了一个独一无二的、资源配比恰到好处的 Agent 执行图(G),实现了真正的 “查询感知(Query-aware)”。
第三板斧:双轨 “进化引擎” – 成本约束下的优化
生成了临时团队去执行任务还不够,MaAS 还要能从经验中学习,让整个 “超网” 和 “算子” 都变得越来越强。但这里有个难题:整个 Agent 执行过程是 “黑盒” 的,充满了与外部工具、API 的交互,无法进行端到端的梯度反向传播!为此,MaAS 采用了双轨优化策略,分别对 “架构分布” 和 “算子本身” 进行更新:
1. 架构分布 (π) 的进化 – 蒙特卡洛策略梯度:
-
MaAS 的目标函数不仅要考虑任务完成得好不好(Performance),还要考虑花了多少钱(Cost,如 token 数)。
-
它通过蒙特卡洛采样来估计梯度。简单说,就是让采样出的几个不同架构(G_k)都去试试解决问题。
-
然后,根据每个架构的 “性价比”(即性能高、成本低)赋予其一个重要性权重 (m_k)。
-
最后,用这个权重来更新超网的概率分布 π,让那些 “又好又省” 的架构在未来更容易被采样到。
2. 算子 (O) 本身的进化 – Textual Gradient (文本梯度):
这是最 “魔法” 的地方!如何优化一个 Prompt 或者一段 Python 代码?MaAS 借鉴了 “文本梯度” 的概念。
它会利用一个梯度智能体,来分析某个算子(比如 Debate 算子)的表现。
如果表现不佳,这个 “教练” 会生成一段文本形式的 “改进意见”,这就是 “文本梯度”。比如:
-
“给这个 Refine 过程的 Prompt 里增加一个 few-shot 示例。”
-
“为了稳定性,降低这个 Ensemble 模块里 LLM 的 temperature。”
-
“给这个 Debate 算子增加一个‘反对者’角色,以激发更深入的讨论。”

图 3 文本梯度案例
性能、成本、通用性:全都要!
MaAS 的效果不仅理念先进,数据更是亮眼。

图 4 MaAS 与其他多智能体方法性能比较
如上图所示,在 GSM8K、MATH、HumanEval 等六大主流基准测试上,MaAS 全面超越了现有的 14 个基线方法,性能提升了 0.54% ~ 11.82%。 平均得分高达 83.59%,展示了其卓越的通用性和高效性。
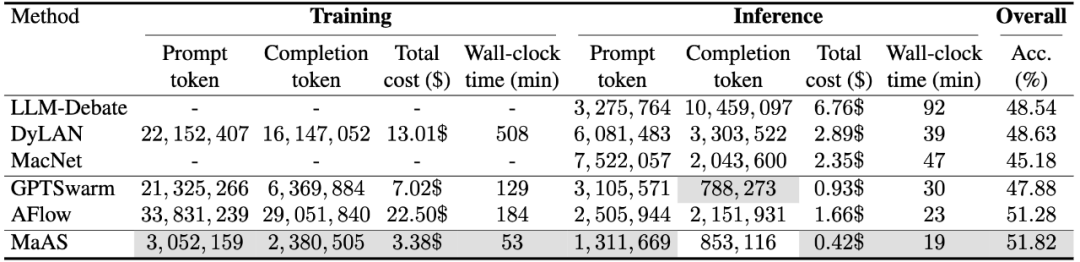
图 5 训练与推理成本比较
成本大降是更令人兴奋的一点。MaAS 所需的推理成本(如 token 消耗)平均只有现有自动化或手动系统的 45%。在 MATH 基准上,MaAS 的训练成本仅为 3.38 美元,而表现相近的 AFlow 则高达 22.50 美元,相差 6.8 倍。除此之外,MaAS 的优化时间仅需 53 分钟,远低于其他动辄数小时的方法。

图 6 MaAS 成本可视化
上图同样展示了 MaAs 在训练 token 消耗、推理 token 消耗和推理 API 金额方面的卓越性能。

图 7 MaAS 推理动态展示。可以看到,针对不同难度的 query,MaAS 智能地激活了不同的智能体网络架构解决之。
上图是 MaAS 对于不同难度的 query 的激活动态。可以看到,MaAS 完美地做到了任务难度的动态感知,对于简单的任务早早地退出了推理过程,而对于复杂的任务则深入 3~4 层智能体超网络 u,并且每层激活的智能体算子不止一个。
除此之外,MaAs 还展示出了超强泛化能力:
-
跨模型:在 gpt-4o-mini 上优化好的 “超网”,可以轻松迁移到 Qwen-2.5-72b 和 llama-3.1-70b 等不同的大模型上,并带来显著的性能提升。
-
跨数据集:在 MATH 上训练,在 GSM8K 上测试,MaAS 依然表现出色,证明了其强大的跨领域泛化能力。
-
对未知算子:即使在训练中从未见过 “Debate” 这个算子,MaAS 在推理时依然可以合理地激活并使用它,展现了惊人的归纳能力。
总结
MaAS 通过引入 “智能体超网” 的概念,巧妙地将 NAS 的思想范式应用到多智能体系统的自动化设计中,完美解决了当前领域 “一刀切” 设计所带来的资源浪费和性能瓶颈问题。它不再追求一个静态的最优解,而是转向优化一个动态生成的架构分布,为不同任务提供量身定制的、最高性价比的解决方案。这项工作无疑为构建更高效、更经济、更智能的全自动化 AI 系统铺平了道路。
让我们共同期待一个完全自动化、自组织、自进化的集体智能时代的到来!
©
(文:机器之心)