又一个Deep Research来了!1-2分钟抵人类专家数小时,所有人免费

Perplexity 推出 Deep Research 功能,提供免费生成深度研究报告服务。它支持多个领域,并在人类最后一次考试中取得高水平成绩。
Perplexity 推出 Deep Research 功能,提供免费生成深度研究报告服务。它支持多个领域,并在人类最后一次考试中取得高水平成绩。

AIxiv专栏介绍及最新研究成果MakeAnything通过Diffusion Transformer与非对称LoRA,实现了从结果到过程的转化,并在多个实验任务中取得了良好的效果。

MLNLP是国内外知名的人工智能社区,致力于促进机器学习与自然语言处理领域的学术交流和技术进步。文章讨论了Reinforce++和GRPO作为PPO变体的应用及其改进,包括去除critic模型、使用远程奖励模型以及在GRPO基础上优化KL估计方法等技术进展。
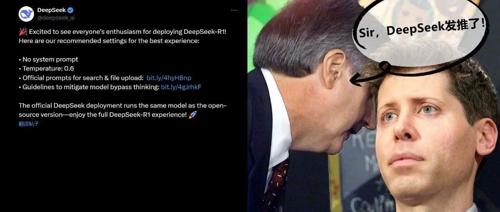
MLNLP社区是一个国内外知名的机器学习与自然语言处理社区,旨在促进学术界、产业界和爱好者的交流与进步。近日,DeepSeek推荐了其官方部署设置,包括不使用系统提示词、温度参数设置为0.6等建议。

理模型)异常火爆,Kimi 和 DeepSeek 陆续推出自家的产品 K1.5 和 R1,效果追评甚