


在人工智能领域,时间推理能力一直是大型语言模型(LLMs)的薄弱环节。尽管这些模型在语言理解、生成和复杂推理任务中表现出色,但在处理时间相关的任务时,如预测未来事件的时间或生成合理的未来场景,它们往往显得力不从心。为了突破这一瓶颈,伊利诺伊大学香槟分校的研究团队开发了Time-R1。
一、项目概述
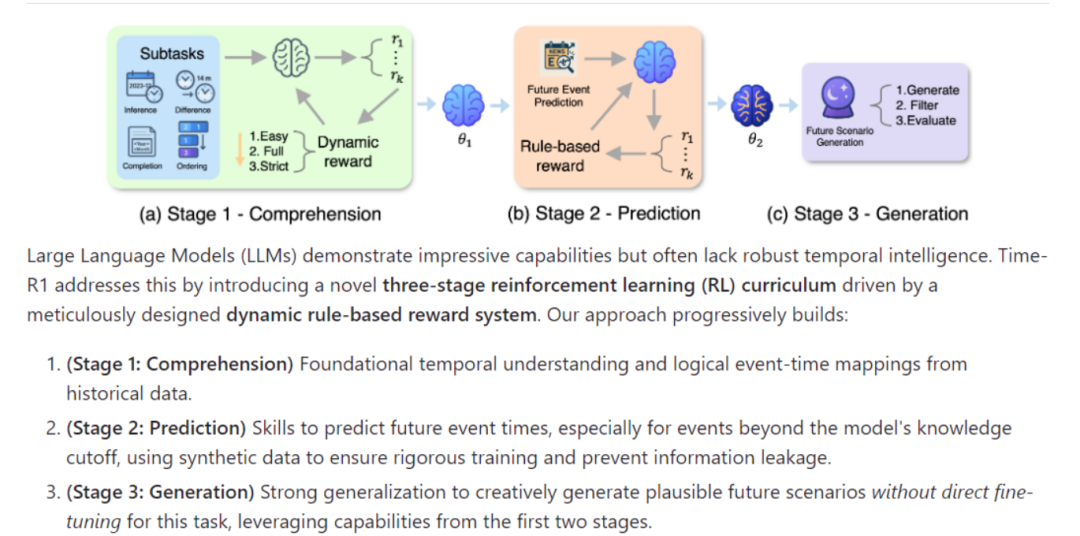
Time-R1 是伊利诺伊大学香槟分校研究团队开发的基于3B参数的语言模型,旨在通过强化学习训练方法赋予语言模型全面的时间推理能力,包括理解、预测和创造性生成。该模型通过三个阶段的训练——理解、预测和生成——逐步建立强大的时间逻辑映射,并能够对未来事件进行准确预测和合理场景生成。Time-R1 在多个时间推理任务中表现优异,甚至超越了参数量大得多的模型,如671B参数的 DeepSeek-R1。

二、技术原理
Time-R1 的技术原理基于一个创新的三阶段强化学习训练框架,结合动态奖励机制和策略优化算法,逐步提升模型的时间推理能力。
(一)三阶段强化学习训练框架
1. 第一阶段:理解(Comprehension)
-
目标:通过基础时间任务(如时间戳推断、时间差估计、事件排序和掩码时间实体补全)对模型进行强化微调,帮助其建立事件与时间的映射关系。
-
数据来源:使用2016年至2023年的纽约时报新闻文章作为训练数据。
-
方法:利用强化学习(RL)对模型进行微调,确保其能够准确理解时间信息。
-
奖励机制:采用动态奖励机制,根据任务难度和训练进程自适应调整奖励权重。
2. 第二阶段:预测(Prediction)
-
目标:在第一阶段的基础上,进一步训练模型以预测未来事件的具体时间。
-
数据来源:使用2024年1月至7月的真实新闻数据,以及2024年8月至2025年2月的合成数据。
-
方法:通过强化学习继续训练模型,使其能够基于历史规律推演未来事件。
-
奖励机制:采用严格的奖励标准,确保模型对未来的预测尽可能准确。
3. 第三阶段:生成(Generation)
-
目标:利用前两个阶段获得的能力,生成合理的未来场景。
-
方法:模型直接生成指定未来时间下的假设新闻事件,无需额外训练。
-
评估:通过与真实新闻事件的语义相似度评估生成场景的合理性。
(二)动态奖励机制
-
通用奖惩设计:包括格式遵循奖励、标签结构奖励和长度与重复惩罚等,确保模型输出格式正确且避免冗长重复。
-
特定任务的精准“标尺”:针对每个时间任务的特性设计准确度奖励,如时间戳推断任务中,奖励基于推断日期与真实日期之间的月份差距。
-
动态调整奖励权重:根据任务难度和训练进程自适应调整衰减系数α,引导模型逐步掌握复杂时序逻辑。
(三)策略优化
使用群组相对策略优化(GRPO)解决策略梯度估计的高方差问题,通过计算相对于其他响应的优势,提供更稳定的学习信号。
三、主要功能
(一)基础时间观念建立
通过四大特训任务(时间戳推理、时间差计算、事件排序、时间实体补全)强化微调,使模型能够精准建立事件与时间的映射关系。
(二)历史事件推理
能够对历史事件的时间顺序、时间间隔等进行准确推理和判断,更好地理解过去发生的事情及其时间背景。
(三)未来事件时间预测
在严格隔离未来数据的前提下,基于历史规律自主推演趋势,预测超出其知识截止日期的事件的具体时间。实验表明,Time-R1 在未来事件时间预测中取得了最高分。
(四)趋势预测
通过对历史数据的学习和分析,预测未来的发展趋势和走向,为决策提供支持。
(五)未来场景生成
无需额外训练,直接生成指定未来时间下合理的推演未来场景,展现出较强的创造性。
(六)内容创作
在新闻和媒体领域,可以基于时间线索创作相关的报道、评论等内容。
四、应用场景
(一)内容创作
基于历史事件和趋势预测未来新闻事件,帮助记者和编辑快速生成新闻标题和内容。
(二)市场分析
通过预测经济指标和市场趋势,为投资者提供决策支持。
(三)历史教学
帮助学生更好地理解历史事件的时间顺序和因果关系,通过生成历史事件的时间线和背景信息,增强学生的学习兴趣和理解能力。
(四)疾病预测
分析历史医疗数据,预测疾病的爆发趋势和传播路径,为公共卫生部门提供预警和应对建议。
(五)技术预测
分析技术发展的历史数据,预测未来技术的突破和应用,为企业的技术研发和创新提供指导。
五、快速使用
Time-R1 的代码和模型已经开源,用户可以通过以下步骤快速部署和使用:
(一)环境准备
硬件要求:建议使用至少4块 NVIDIA A6000 GPU。
软件环境:需要安装 Python 3.8 及以上版本,并配置好 PyTorch 环境。
(二)代码获取
从Time-R1的GitHub 仓库克隆代码:
git clone https://github.com/ulab-uiuc/Time-R1.gitcd Time-R1pip install -r requirements.txt
(三)加载预训练模型
# Load model directlyfrom transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("ulab-ai/Time-R1-Theta2")model = AutoModelForCausalLM.from_pretrained("ulab-ai/Time-R1-Theta2")input_text = "预测2025年5月的商业趋势"inputs = tokenizer(input_text, return_tensors="pt")outputs = model.generate(**inputs, max_length=200)print(tokenizer.decode(outputs[0]))
(四)运行示例任务
时间戳推断:
input_text = "<think>2023年发布的AI论文,通常次年2月公布完整报告。</think>预测该报告发布时间。"未来场景生成:
input_text = "生成2025年6月关于AI技术突破的新闻标题"六、结语
Time-R1 通过创新的三阶段强化学习训练方法,显著提升了语言模型的时间推理能力,为 AI 领域的时间感知和未来预测提供了新的思路和工具。其开源的代码和数据集为研究者和开发者提供了丰富的资源,有助于进一步推动时间推理技术的发展。未来,Time-R1 可以在更多领域发挥重要作用,如智能交通、金融风险预测等。我们期待更多开发者和研究者加入这一领域,共同探索时间推理的无限可能。
七、项目地址
GitHub 仓库:https://github.com/ulab-uiuc/Time-R1/tree/master
HuggingFace模型库:https://huggingface.co/collections/ulab-ai/time-r1
arXiv 技术论文:https://arxiv.org/pdf/2505.13508
(文:小兵的AI视界)