
DeepSeek华为火线联手!硅基流动首发即限流,全国产API白菜价,零门槛部署
华为DeepSeek与SiliconCloud联合推出硅基流动,提供基于昇腾云服务的DeepSeek-V3、DeepSeek-R1模型,价格便宜且支持零部署门槛。用户可在Web端/手机端使用,并可免费体验多模态模型Janus-Pro-7B。
华为DeepSeek与SiliconCloud联合推出硅基流动,提供基于昇腾云服务的DeepSeek-V3、DeepSeek-R1模型,价格便宜且支持零部署门槛。用户可在Web端/手机端使用,并可免费体验多模态模型Janus-Pro-7B。

OpenAI发布o3-mini系列最新推理模型,包含low、medium和high三个版本。其针对STEM领域进行了优化,并提供免费访问。对比DeepSeek-R1,o3-mini虽然价格更高,但响应更快,数学能力和科学能力表现优于前代。

DeepSeek-R1的崛起引起了国际上的广泛关注。它不仅受到云服务厂商和英伟达等巨头的关注,还在RAG(检索增强生成)技术上展示了出色的能力。百度通过其文心一言大模型展示出在这一领域的领先地位,并且吴恩达认为中国的大模型与顶尖水平之间的差距正在缩小。
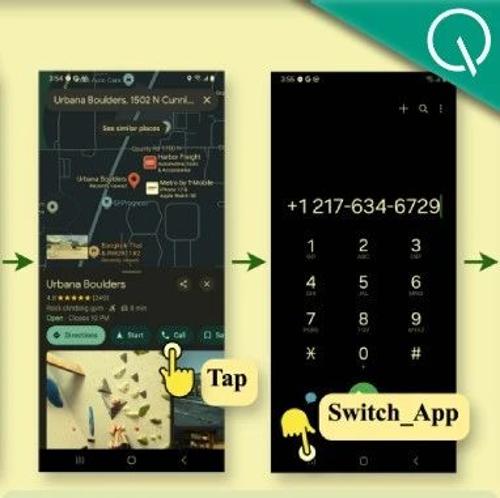
UIUC与阿里通义实验室联合推出Mobile-Agent-E,这是一种新型手机智能体框架。它利用多层级多智能体架构来处理复杂的真实场景任务,并引入自我进化模块以增强其学习能力。

硅谷AI巨头纷纷支持DeepSeek,包括OpenAI、微软、英伟达等。OpenAI寻求新一轮400亿美元融资,估值翻番至3000亿美元。同时,Cursor和DeepSeek-R1模型已上线相关平台,引发业界广泛关注与讨论。

北大课题组通过将语言数据集和GPT模型展开为蒙特卡洛语言树(Data-Tree 和 GPT-Tree),揭示了现有大模型拟合训练数据的本质是寻求一种更有效的近似方法。同时,作者提出大模型中的推理过程可能是概率模式匹配而非形式推理。

首个FP4精度的大模型训练框架发布,可使所需存储和计算资源更少。与BF16相当的训练效果下,最高可达130亿参数规模的模型。研究团队采用定制化的FP4矩阵乘法、不同粒度量化策略以及新的梯度估计方法。

清华大学THUNLP团队联合东北大学NEUIR、面壁智能及9#AISoft团队推出的UltraRAG框架革新了RAG系统的开发与配置方式,提供一键式便捷操作和模块化设计,显著降低学习成本和开发周期。
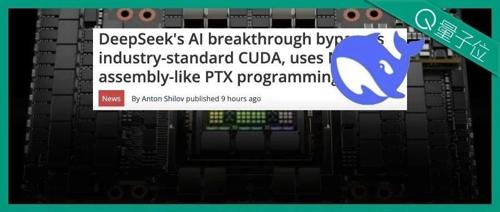
英伟达新硬件优化论文《DeepSeek-V3》绕过CUDA直接使用PTX编程语言进行优化,大幅提升硬件效率。专家指出这不代表完全脱离CUDA生态,而是展示出优化其他GPU的能力,并引发了对AI是否能编写底层代码的讨论。
