DeepSeek-R1秘籍轻松迁移,最低只需原始数据0.3% 邱锡鹏团队联合出品

研究人员提出MHA2MLA方法,通过微调预训练模型减少KV缓存大小90%,保持甚至提升性能。该技术利用低秩联合压缩键值技术和分组查询注意力策略,降低推理成本的同时维持精度。
研究人员提出MHA2MLA方法,通过微调预训练模型减少KV缓存大小90%,保持甚至提升性能。该技术利用低秩联合压缩键值技术和分组查询注意力策略,降低推理成本的同时维持精度。
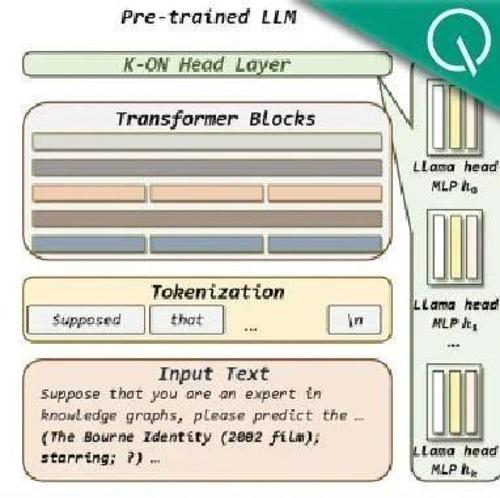
蚂蚁联合实验室提出了一种名为K-ON的方法,利用多词元并行预测机制使大语言模型能够感知知识图谱知识。该方法通过实体层级的对比学习实现了高效的知识图谱补全任务,并在多个数据集上取得了优于现有方法的结果。

百度回归 ‘百度一下 你就知道’ 概念,结合AI技术提升了搜索结果的个性化和多模态内容。升级后的百度APP不仅提供了更精准的答案,还整合了语音、绘图等功能,并接入了DeepSeek-R1模型。这些变化反映了百度在向“内容化”转变的同时也在提升用户服务体验。

DeepSeek开源FlashMLA第一天,H800 GPU计算性能提升至3000GB/s、580TFLOPS。网友称赞工程团队实现每FLOP的突破。

中科闻歌发布智川X-Agent和优雅平台,助力政企快速落地AI应用与创意灵感。智川X-Agent提供一站式开发平台,支持零代码构建个性化智能体;优雅平台则为多模态内容生成提供智能体支持。

OpenAI团队的优化算法Muon在更大模型和数据集上的应用效果被月之暗面团队验证,改进后的Muon对1.5B参数量Llama架构模型的算力需求仅为AdamW的52%,同时基于DeepSeek架构训练出一个16B的MoE模型并开源。