
 NLP工程化
NLP工程化
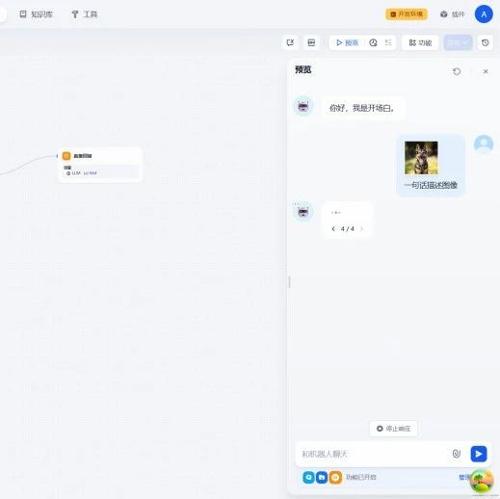

Dify工作流中的LLM节点:Dify中LLM结构化输出功能检查
本文介绍使用Dify v1.4.0版本和qwen-vl-max-latest多模态大模型检查LLM结构化输出功能的执行流程,包括方法返回状态、提前退出检查、获取模型信息以及检查模型能力等步骤。
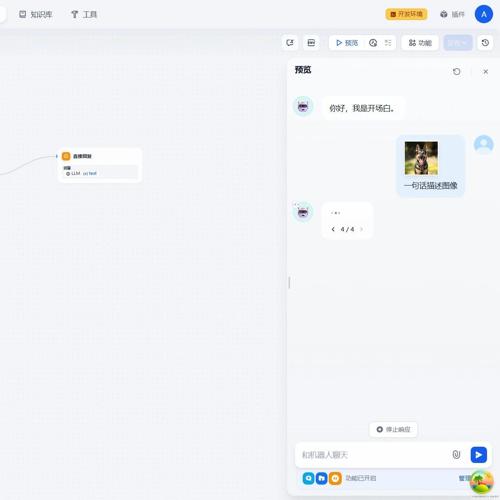
Dify工作流中的LLM节点:_fetch_memory方法
本文介绍Dify v1.4.0版本中使用qwen-vl-max-latest作为多模态大模型的工作流中的LLM节点的_fetch_memory方法执行流程,包括参数检查、获取对话ID、数据库查询和创建TokenBufferMemory实例等步骤。
llm-speedrunner:自动化LLM Speedrunning挑战基准
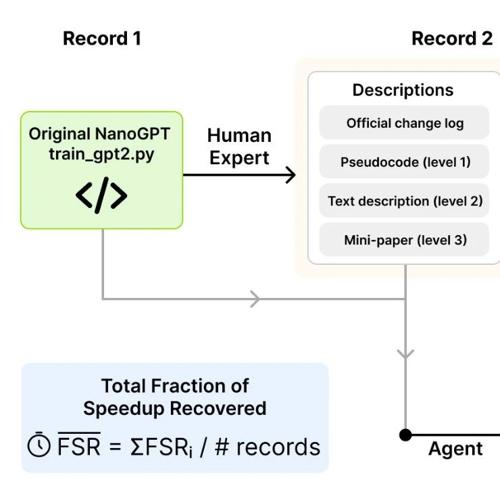
自动化LLM Speedrunning挑战基准,评估前沿LLM Agent复现科学发现和创新的能力,涵盖多种提示格式、实验设置和扩展框架。
TokenDagger:高性能实现OpenAI的TikToken,为大规模文本处理加速
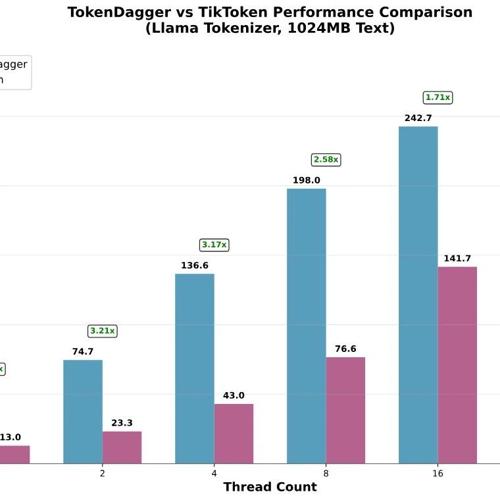
TokenDagger加速OpenAI的TikTok实现,代码样本分词速度提升4.02倍,采用优化正引擎和简化BPE算法降低大词汇表损耗。
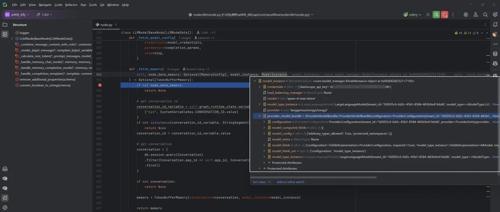
commands.py中的migrate_knowledge_vector_database()函数解析
wledge_vector_database()
函数的执行逻辑。源码位置:dify\api\com